
本文主要介绍“Linux进程内存管理实例分析”。在日常操作中,对于Linux进程内存管理的实例分析问题,相信很多人都有疑问。边肖查阅了各种资料,整理出简单易用的操作方法,希望能帮你解答“Linux进程内存管理实例分析”的疑惑!接下来,请和边肖一起学习!
00-1010一个进程的虚拟地址空间主要用两个数据结来描述,一个是mm_struct,另一个是vm _ area _ structs。
Mm_struct结构描述了进程的整个虚拟地址空间,vm_area_truct描述了虚拟地址空间的一个区间(简称virtual area)。下图显示了从task_struct到mm_struct的进程地址空间分布。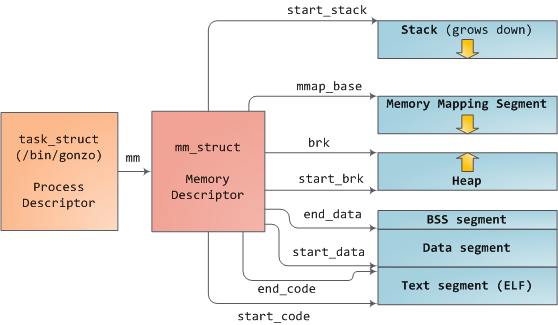
每个进程都会有自己独立的mm_struct,这样每个进程都会有自己独立的地址空间,这样才不会互相干扰。当进程之间的地址空间被共享时,我们可以理解为多个进程此时使用一个地址空间,这就是一个线程。
structmm_struct
{
structvm _ area _ struct * mmap//指向虚拟区间(VMA)链表
structrb _ rootmm _ rb//指向红黑树
struct VM _ area _ struct * mmap _ cache;//查找最近的虚拟间隔
unsignedlong(* get _ unmapped _ area)(struct file * filp,unsignedlongaddr,unsignedlonglen,unsignedlongpgoof,unsignedlongflags);
void(* unmap _ area)(struct mm _ struct * mm,unsignedlongaddr);
unsignedlongmmap _ base
unsignedlongtask _ size//拥有该结构的进程的虚拟地址空间的大小。
unsignedlongcached _ hole _ size
unsignedlongfree _ area _ cache
pgd _ t * pgd//指向页面全局目录
atomic _ tmm _ users//用户空间有多少用户?
atomic _ tmm _ count//有多少对“structmm_struct”的引用
intmap _ count//虚拟间隔的数量
structure w _ semaphore
nbsp;mmap_sem;
spinlock_t page_table_lock; //保护任务页表和mm->rss
struct list_head mmlist; //所有活动mm的链表
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
unsigned long hiwter_rss;
unsigned long hiwater_vm;
unsigned long total_vm,locked_vm,shared_vm,exec_vm;
usingned long stack_vm,reserved_vm,def_flags,nr_ptes;
unsingned long start_code,end_code,start_data,end_data; //代码段的开始start_code ,结束end_code,数据段的开始start_data,结束end_data
unsigned long start_brk,brk,start_stack; //start_brk和brk记录有关堆的信息,start_brk是用户虚拟地址空间初始化,brk是当前堆的结束地址,start_stack是栈的起始地址
unsigned long arg_start,arg_end,env_start,env_end; //参数段的开始arg_start,结束arg_end,环境段的开始env_start,结束env_end
unsigned long saved_auxv[AT_VECTOR_SIZE];
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
mm_counter_t context;
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags;
struct core_state *core_state;
}
-
分配的每个虚拟内存区域都由一个vm_area_struct 数据结构来管理,包括虚拟内存的起始和结束地址,以及内存的访问权限等,通常命名为vma;vm_area_struct 数据结构的定义如下:
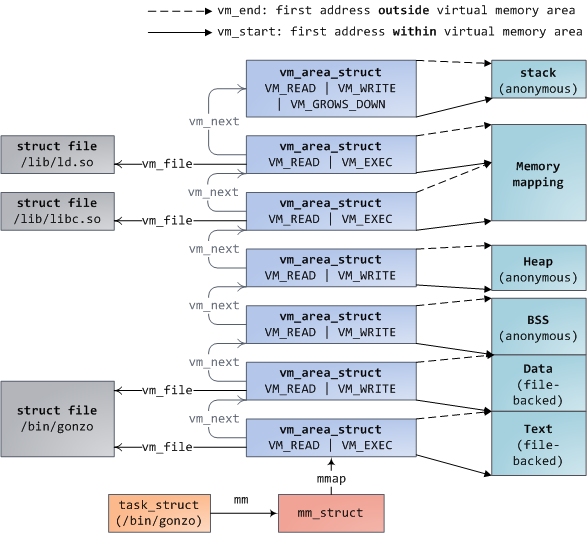

struct vm_area_struct {
/* The first cache line has the info for VMA tree walking.
第一个缓存行具有VMA树移动的信息*/
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address
每个任务的VM区域的链接列表,按地址排序*/
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
此VMA左侧最大的可用内存间隙(以字节为单位)。
在此VMA和vma-> vm_prev之间,
或者在VMA rbtree中我们下面的一个VMA与其->vm_prev之间。
这有助于get_unmapped_area找到合适大小的空闲区域。
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here.
第二个缓存行从这里开始*/
struct mm_struct *vm_mm; /* 我们所属的address space*/
pgprot_t vm_page_prot; /* 此VMA的访问权限 */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
对于具有地址空间(address apace)和后备存储(backing store)的区域,
链接到address_space->i_mmap间隔树,或者链接到address_space-> i_mmap_nonlinear列表中的vma。
*/
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} linear;
struct list_head nonlinear;
} shared;
/*
在其中一个文件页面的COW之后,文件的MAP_PRIVATE vma可以在i_mmap树和anon_vma列表中。
MAP_SHARED vma只能位于i_mmap树中。
匿名MAP_PRIVATE,堆栈或brk vma(带有NULL文件)只能位于anon_vma列表中。
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem & * page_table_lock
由mmap_sem和* page_table_lock序列化*/
struct anon_vma *anon_vma; /* Serialized by page_table_lock 由page_table_lock序列化*/
/* 用于处理此结构体的函数指针 */
const struct vm_operations_struct *vm_ops;
/* 后备存储(backing store)的信息: */
unsigned long vm_pgoff; /* 以PAGE_SIZE为单位的偏移量(在vm_file中),*不是* PAGE_CACHE_SIZE*/
struct file * vm_file; /* 我们映射到文件(可以为NULL)*/
void * vm_private_data; /* 是vm_pte(共享内存) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU映射区域 */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* 针对VMA的NUMA政策 */
#endif
};
小实验
-
insmod test.ko pid_mem=3253 显示各个vma区域
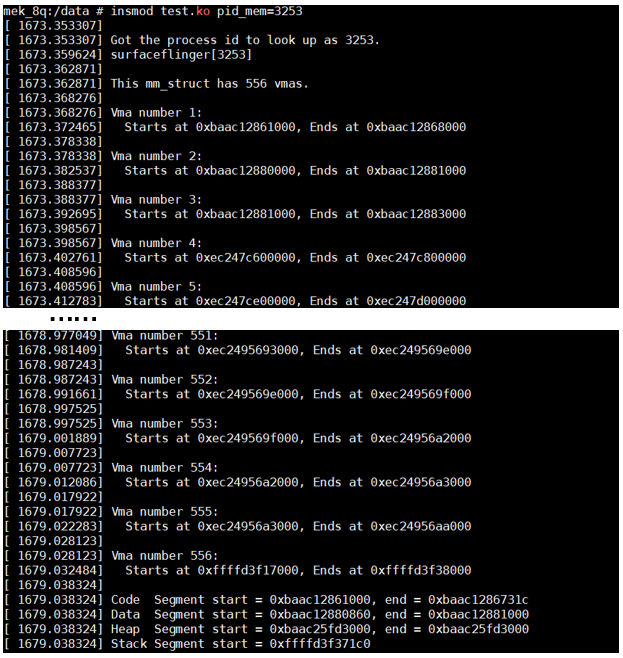
-
cat /proc/3253/maps 显示各个vma区域

看下两种方式的对比:
到此,关于“Linux进程的内存管理举例分析”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注网站,小编会继续努力为大家带来更多实用的文章!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/113135.html