
本文将详细解释如何使用PostgreSQL,一个用于调整查询成本的数据库。文章内容质量较高,边肖将分享给大家参考。希望你看完这篇文章后有所了解。
大多数数据库无法在查询中更改成本评估的成本指数。假设我的系统从10,000 rpm磁盘换成可以提供每秒1366MB/S的老方法SSD查询评估,对数据库系统的查询性能有多大帮助?
PG在这方面的特殊功能是什么?让我们往下看。在此之前,我们还需要知道PG是这些数据库中唯一的一个,不能在语句中强制添加,也不能强制索引。
或者索引数据库。(pg_hint_plan可以解决这个问题)
以下是检查查询中成本的方法。

我们再深入一点。从下面两张图中我可以看出一些东西。在第一个图中,我们可以看到查询执行计划中的Starup成本为0。
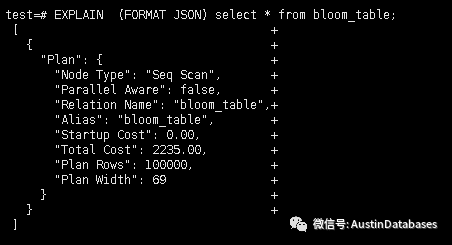
以下查询的查询计划,启动成本,整体成本与启动成本相同。
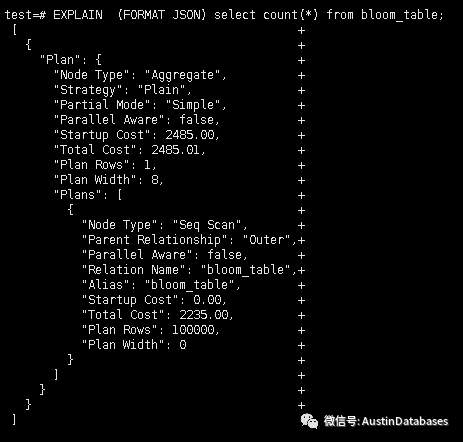

实际上,总成本等于启动成本和运行成本。
另外,以第一列为例,顺序扫描没有启动成本,只有运行成本。

总费用是2235。这个2235是怎么来的?

让我看一下bloom_table占用的表行数和PAGE。
运行成本通过以下公式CPU运行成本磁盘的运行成本)*每页消耗多少行顺序扫描*多少页?
(0.01 0.0025) *100000 1.0 * 1235=1250 1235=2235
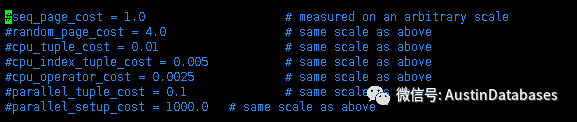
其中,0.01 0.0025 1分别来自上图。
seq_page_cost=1.0
cpu_tuple_cost=0.01
cpu_operator_cost=0.0025
,这意味着可以通过调整系统中的参数来改变一条语句的成本,其他数据库在这方面基本都是封闭的。
让我们看看如果我们离开指数,如何计算成本。

索引的成本将包括启动成本,从索引的第一个元组开始。
起始成本(索引)=舍入{log(2)(有多少个索引行)(Hindex 1) * 50} * CPU运行消耗

相关消耗=四舍五入(log2 100000 (2 1)* 50)* 0.0025=0。
42 (约等于实际是0.4175)
这里面有两个问题,1 HINDEX 到底是这么来的,这里面指的是索引的树高,其实可以通过这个公式来推出你的索引树有多高
运行的代价 (索引使用的CPU 代价 + 表使用CPU的代价) + (index_io 代价 + 表的io 代价)
在计算索引的代价中会涉及到选择率的问题,意思就是查询的谓词的频率的估计。
下面就是通过SQL 语句来给出每行的值来计算一个“采样率”的东西,也就是告诉你,这个行的值在整体的表中的占比。
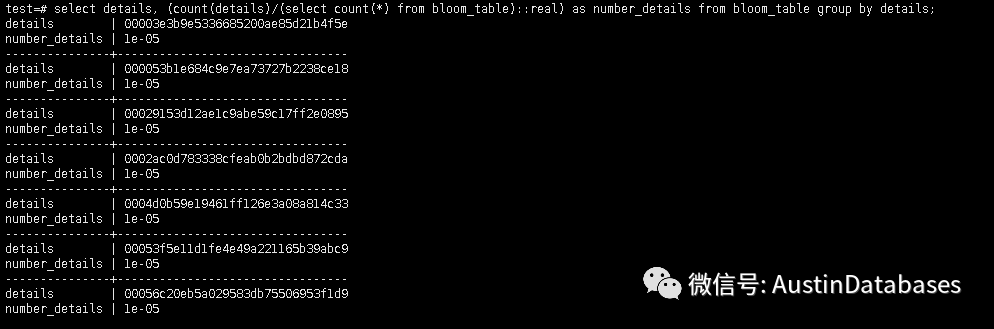
这里由于计算比较麻烦,就不进行计算了,但这里需要注意的是
random_page_cost = 4.0 ,这个是在查询中使用索引计算 index_io_cost的一个标量,通过选择率 * index的page的数量 * random_page_cost 就可以得出索引的io cost ,而到底是走索引还是走全表扫描,执行计划会进行比对,如果走全表扫描会计算最小和最大的io cost,例如最大的 io_cost = 页面的数量 * random_page_cost
所以调整 random_page_cost 的值会影响到底是走索引还是走全表扫描的选择性。
下面可以举一个例子,我将配置文件中的random_page_cost 和 cpu_index_tuple_cost 进行调整,一个调小 一个调大,可以看到下图的结果,就算我有10万条记录,并且我查询的条件中的字段10万条那条都和那条不一样,并且也建立了相关的索引,最终的结果还是进行了全表扫描。

在将两个参数还原后,还是继续走原来的索引

说了这么多其实回到我开头说的问题,如果你的磁盘系统已经更改到SSD 磁盘则你的某些值是需要改变,否则可能会出现一些明明索引很好,但他选择全表扫描的情况。
关于调整查询代价的数据库PostgreSQL怎么用就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/129607.html