
本文将详细阐述KEGG聚糖数据库的原理。这篇文章的内容质量很高,所以边肖会分享给大家参考。希望大家看完这篇文章能有所了解。
作为复杂碳水化合物糖与蛋白质或脂质结合的产物,广泛分布于生物体内,具有重要功能。多聚糖数据库包含了经过实验验证的复杂碳水化合物的信息,主要是结构信息。每条记录都由G编号标识,如G00197。
对于复杂的碳水化合物,了解其结构只是最基础的研究,我们更关注它在生命活动中的意义。Kegg将与复杂碳水化合物相关的基因、代谢途径和疾病的信息联系起来,并以途径的形式显示出来。在途径数据库中,有一个类别专门描述复杂碳水化合物的代谢途径信息,称为糖生物合成和代谢。

在这些通路中,显示的主要信息是复合碳水化合物的代谢通路、与基因的相互作用等信息,部分图中还包含了复合碳水化合物对应的生物合成通路或降解通路,称为结构图。例如,Map00510可以分为以下两部分:
代谢途径
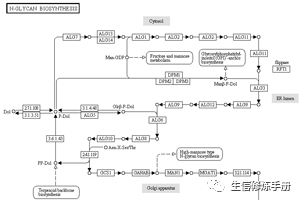
结构图


对于复杂碳水化合物在癌症中的作用,有一种特殊的途径来记录这些信息。
http://www.kegg.jp/kegg-bin/show_pathway?hsa05205
糖基转移酶催化糖与蛋白质、脂类和其他物质的结合。
关于糖基转移酶的信息存储在KO数据库中。例如,下图不仅显示了相应的基因,还显示了相应的酶EC号、CAzy数据库的信息以及参与途径信息。
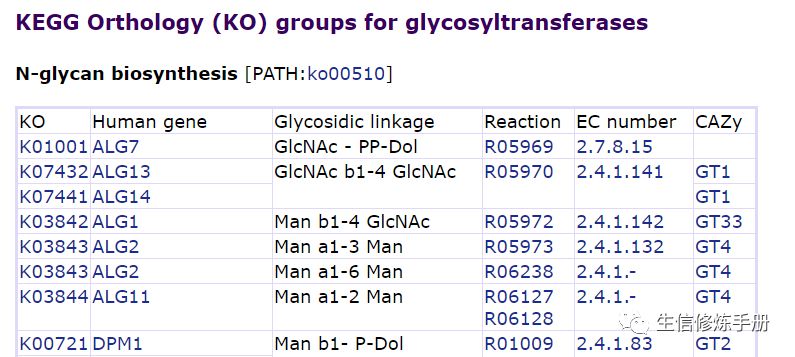
对于所有包含的糖基转移酶的分类,brite数据库中相应的链接如下
http://www.kegg.jp/kegg-bin/get_htext?ko01003 .小桶
总结
聚糖数据库包含糖类物质的结构信息,并给出各种代谢途径的糖类参数。
糖基转移酶催化糖与蛋白质和脂质的结合,在KO数据库中给出相应的信息。
KEGG聚糖数据库的原理呢,希望在这里分享。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/130721.html