
本期,边肖将给大家带来宏基因组原理宁滨。文章内容丰富,从专业角度进行分析和描述。看完这篇文章,希望你能有所收获。
宏基因组
扔掉
也就是说,序列的聚类和包装是根据基因组特征和装配信息分离属于不同基因组的序列的过程。及格
扔掉
得到
垃圾箱
(更准确地说。
应变能级簇
或者
菌株级分类单位
)很可能是实验室无法纯培养的未知微生物的基因组序列,因此用基因组学对其进行分析具有重要意义。
[1
]。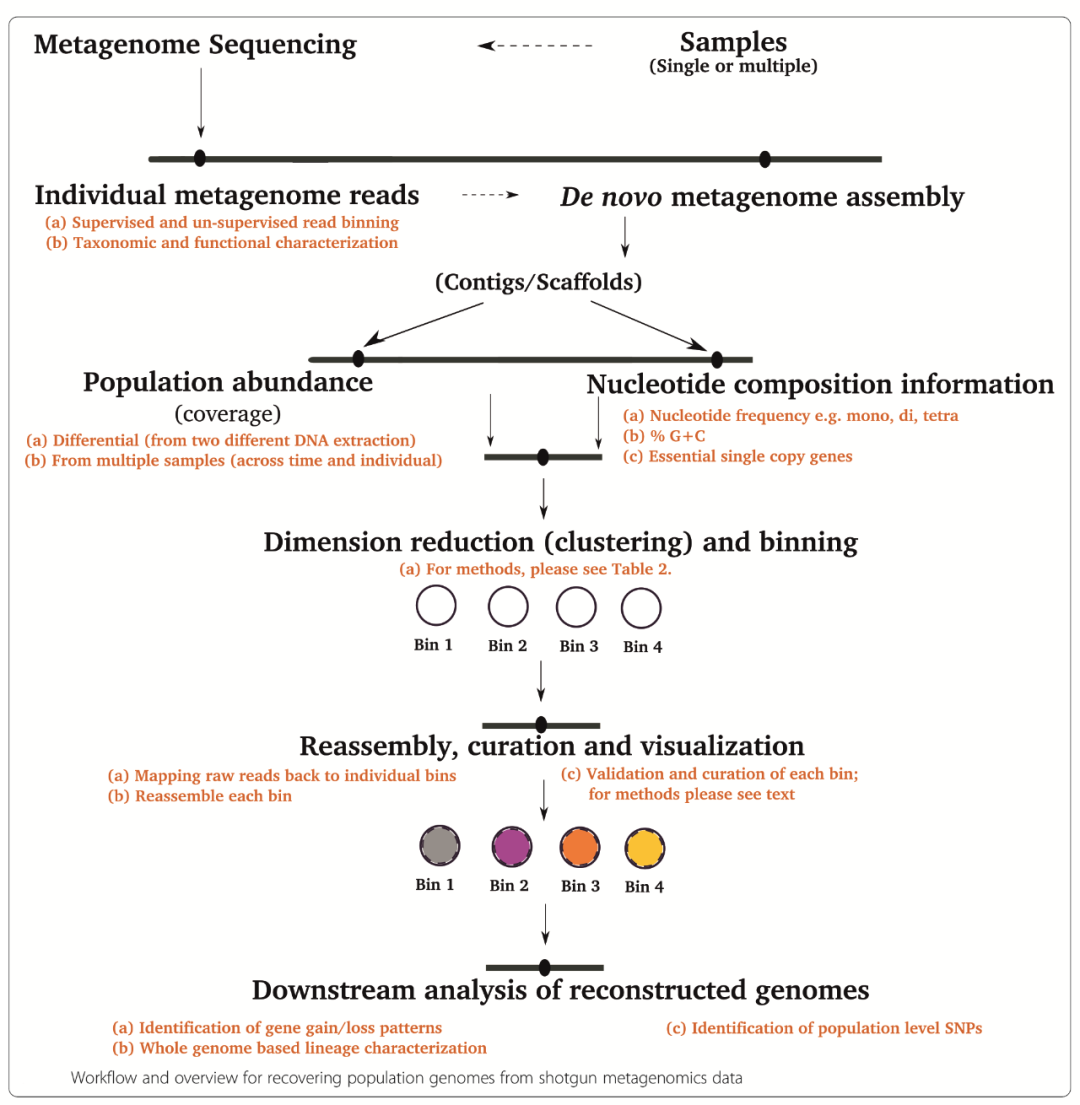

为了从宏基因组中分离单个基因组,可以使用序列特征或序列组装信息。常见的可用信息主要包括以下内容:
A.根据基因组特征的核酸频率(通常为四核苷酸频率)、GC含量和必要的单拷贝基因;
B.根据重叠群序列的覆盖信息确定重叠群序列;
C.根据测序数据的kmer丰度信息,
D.根据不同样品中序列的共现规律(跨多个样品的共丰度模式);
E.通过将序列映射到数据库的参考序列,即物种宁滨获得的注释信息。
根据所使用的序列数据,宁滨策略可以分为三种类型:基于组装前的干净读取、基于组装后的重叠群和基于带注释的基因。
基于对宁滨的解读
预期的基因组深度随着环境中微生物的丰富程度而变化。根据kmer丰度,读数可以直接聚类,以分离属于不同基因组的读数。它的优点是可以聚类出宏基因组中丰度很低的物种,并能分离出亲缘关系较近的物种。考虑到宏基因组组装中读取的利用率很低,在单个样本5Gb测序量的情况下,环境样本组装中读取的利用率一般只有10%左右,肠道样本或极端环境样本组装中读取的利用率一般可以达到30%,导致很多物种尤其是丰度较低的物种的读取没有组装,没有体现在重叠群中而被浪费。因此,基于宁滨读数获得低丰度物种基因组测序数据是可能的。在实际研究中,基于reads宁滨的LSA(潜在菌株分析)方法可以聚类丰度低至0.00001%的物种,并且对同一物种中的不同菌株非常敏感[2]。
基因宁滨上的Based
宏基因组的序列组装和基因预测后,将所有样本中的预测基因混合在一起,通过消除冗余得到唯一的基因集。根据每个样本中基因的丰度变化模式,计算基因之间的相关性,并利用相关性进行聚类。宁滨用这种策略获得的Bins可以称为CAG(共丰度基因群),包含700个以上基因的CAG可以称为MGS(宏基因组种),CAG可以用于关联分析,MGS可以用于单个细菌的后续组装[3]。当然,根据不同的聚类算法和相关系数,基因宁滨得到的仓名是不同的。除此之外,还有MLG(宏基因组连锁群)、MGC(宏基因组集群)和宏基因组操作分类单位)等。同时,MLG、MGC、MGS和梅塔奥图的物种注释标准也有所不同。
目前,在已发表的宏基因组关联分析(MWAS)和多组学联合分析的文章中,许多宏基因组宁滨方法被基因宁滨使用,尤其是在MWAS疾病的研究中[4]。该方法的优点是基于基因丰度变异模式的宁滨法可操作性强,过程简单,重现性强,计算机资源消耗低。
基于宁滨重叠群
集合元基因组后,将所有读取的序列映射到重叠群,获得重叠群覆盖,然后通过整合GC含量、核算组成等信息对重叠群进行聚类,分离出属于不同基因组的重叠群序列。目前广泛使用的是Contig宁滨,最常用的方法是组装单个物种的基因组。目前,基于contig宁滨的软件有多种[1],对丰富的物种Contig宁滨有很好的效果,但仍存在一些缺陷或很大的改进空间,例如核酸组成信息的利用还没有充分开发。四基频因其简单而被广泛使用和接受。然而,一些研究表明k-mer的丰度信息也是一个很好的种系特征。同时,越长的k-mer包含的信息越多,基因和参考基因组之间的同源关系也是有价值的种系信号,但这些还没有被自动化的宁滨软件整合。
扔掉
结果对参数设置非常敏感,但有很多。
扔掉
软件中只有有限的可调参数,因此希望获得高质量。
垃圾箱通常需要手动调节。上面边肖分享的宏基因组宁滨的原理是什么?如果你恰好也有类似的疑惑,可以参考上面的分析来理解。想了解更多,请关注行业信息渠道。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/132968.html