
FP Tree算法的原理是什么?我相信很多没有经验的人都不知所措。因此,本文总结了问题产生的原因及解决方法。希望你能通过这篇文章解决这个问题。
00-1010
Apriori算法是挖掘频繁项集的经典算法,需要多次扫描数据,I/O是很大的瓶颈。为了解决这个问题,FP Tree算法(也称FP Growth算法)采用了一些技巧,无论多少数据,只需要扫描两次数据集,因此提高了算法运行的效率。下面我们就对FP Tree算法做一个总结。
为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据。该数据结构由三部分组成,如下图所示:
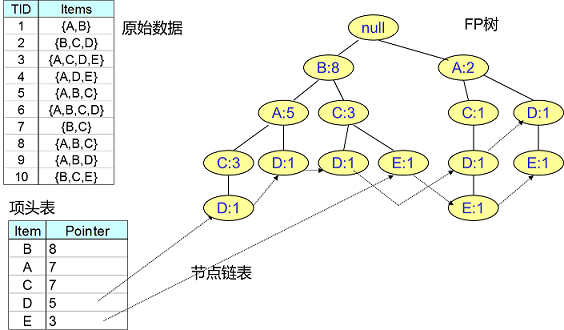

第一部分是项目标题表。所有1个频繁集的出现次数都记录在其中,按降序排列。比如上图中,B在全部10组数据中出现了8次,所以排名第一,很容易理解。第二部分是FP Tree,它将我们的原始数据集映射到内存中的一个FP树。这个FP树很难理解。它是如何建造的?我们以后再谈这个。第三部分是节点链表。所有项目头表中的一个频繁集是节点链表的头,它依次指向频繁集在FP树中出现的位置。这主要是为了方便搜索和更新物料表头和FP Tree的关系,也很容易理解。
下面我们讲项头表和FP树的建立过程。
1. FP Tree数据结构
FP树的建立首先依赖于物料表头表的建立。首先,我们来看看如何建立项目表头表。
我们第一次扫描数据,得到所有频繁项集的计数。然后删除支持度低于阈值的项目,将一个频繁集放入项目表头,按照支持度降序排列。然后,对数据进行第二次和最后一次扫描,并将读取的原始数据从罕见的1项目集中排除,并按支持度降序排列。
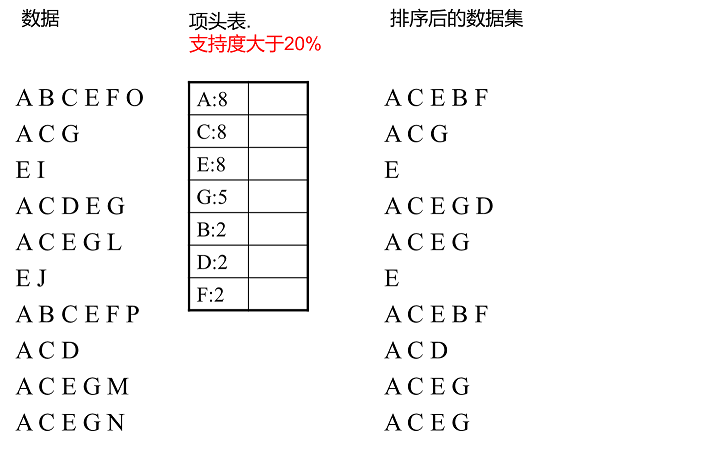
上面这一段很抽象。让我们用下面的例子来详细解释一下。我们有10条数据。首先,我们第一次扫描数据,统计一个项目集。我们发现O、I、L、J、P、M、N都出现一次,并且它们的支持度都在20%的阈值以下,所以它们不会出现在下面的项目表头表中。剩下的A、C、E、G、B、D、F按照支撑程度降序排列,构成了我们的头表。
然后,我们第二次扫描数据。对于每一条数据,我们消除不常见的项目集,并按照支持度的降序排列它们。例如,删除了数据项ABCEFO,其中o是一组不常见的1项,只剩下ABCEF。按照支持的顺序,变成了ACEBF。其他数据项等等。为什么要对原始数据集中的一个频繁数据项进行排序?这是为了我们在后面构建FP树的时候尽可能的共享祖先节点。
通过两次扫描,建立了项目表头,得到了排序后的数据集。我们来看看如何建立FP树。
00-1010有了项目表头和排序后的数据集,我们就可以开始建立FP树了。起初,FP树没有数据。当构建FP树时,我们逐个读取排序后的数据集,并将其插入FP树。插入时,我们根据排序顺序将其插入到FP树中。顺序前面的节点是祖先节点,后面的节点是后代节点。如果存在共享祖先,则相应的公共祖先节点数增加1。插入后,如果出现新节点,表头对应的节点会通过节点链表链接到新节点。直到所有的数据都插入到FP树中,FP树的建立就完成了。
看起来也很抽象。让我们用第二节中的例子来描述它。
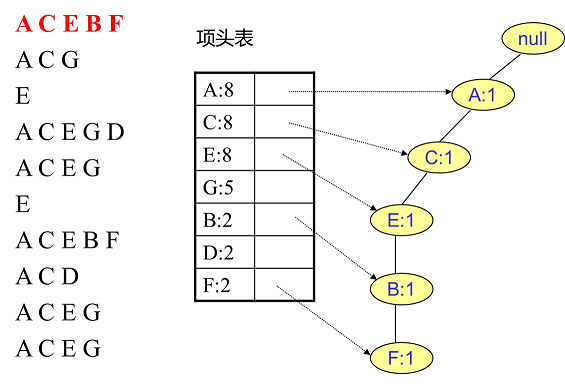
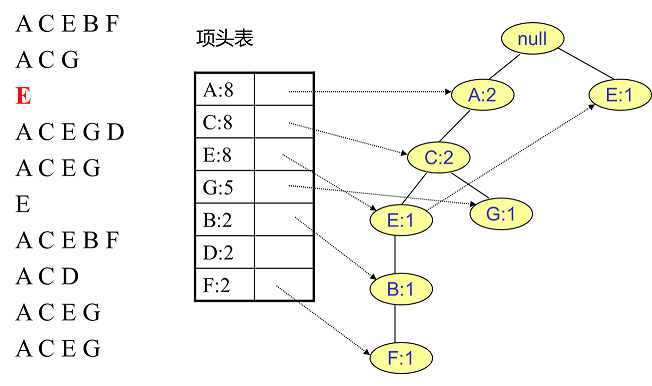
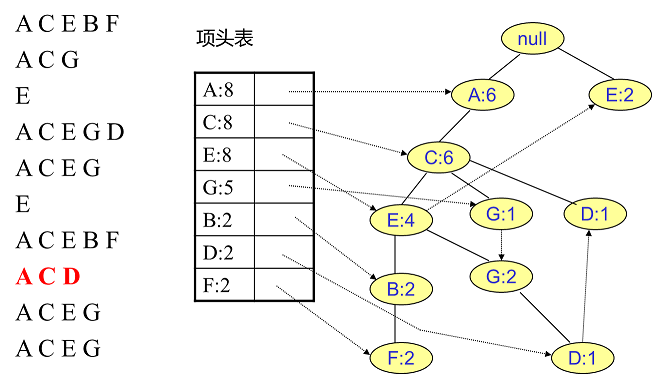
首先,我们插入第一条数据ACEBF,如下图所示。此时FP树没有节点,所以ACEBF是一个独立的路径,所有节点都计数为1,项目头表链接到节点链表上对应的新节点。
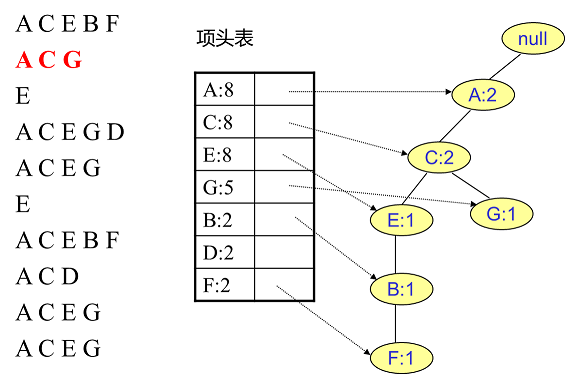
然后我们插入数据ACG,如下图所示。因为ACG和现有的FP树可以有一个共同的祖先节点序列AC,所以只需要添加一个新的节点G,并将新节点G的计数记录为1。同时,A和C的计数加1变成2。当然,对应G节点的节点链表也要更新。
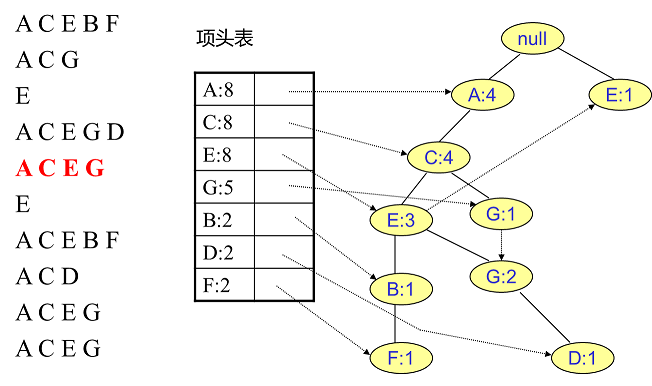
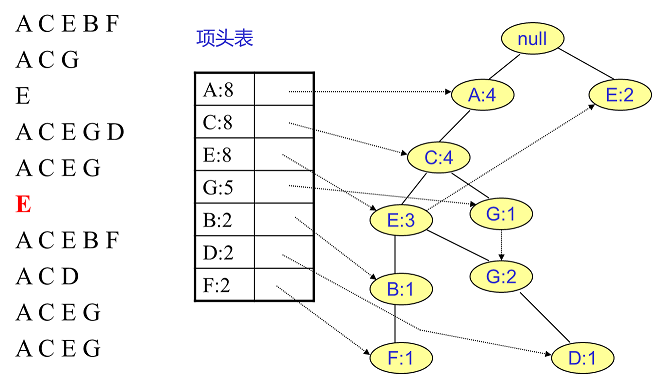
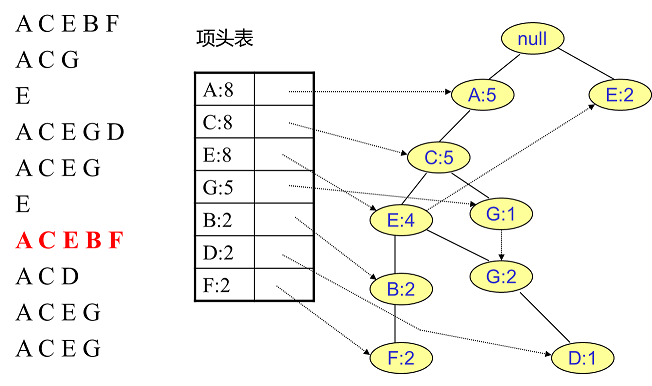
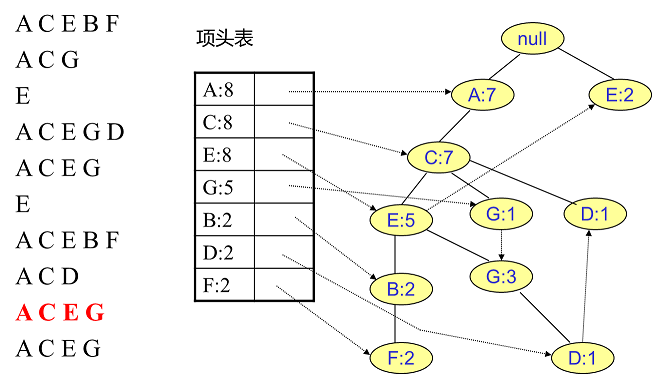
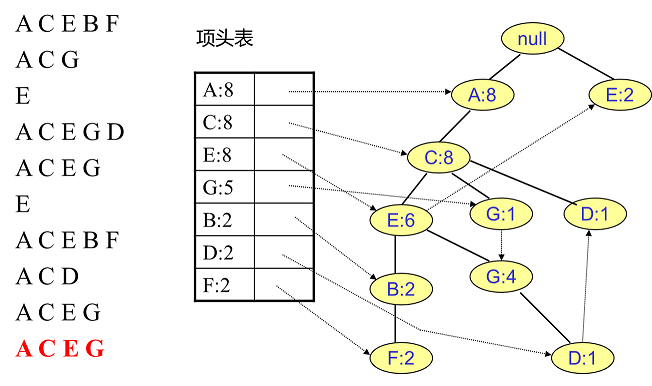
相同的方法可以更新接下来的八个数据,如下图所示。因为原理相似,这里没有太多文字解释,大家可以自己试着插入理解对比一下。相信如果能独立插入这10条数据,建立FP树的过程也不会很难。
upload/information/20210522/347/686080.png" alt="FP Tree算法原理是什么">
4. FP Tree的挖掘
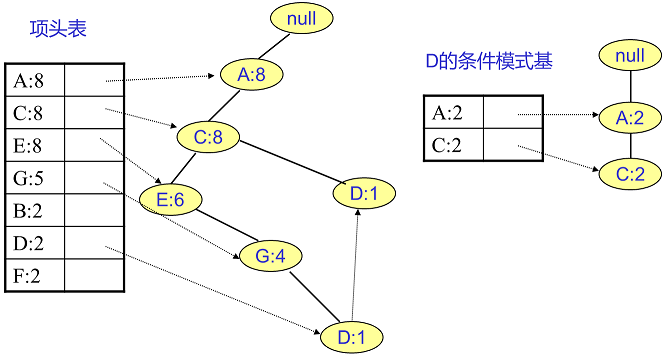
我们辛辛苦苦,终于把FP树建立起来了,那么怎么去挖掘频繁项集呢?看着这个FP树,似乎还是不知道怎么下手。下面我们讲如何从FP树里挖掘频繁项集。得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集了。
实在太抽象了,之前我看到这也是一团雾水。还是以上面的例子来讲解。我们看看先从最底下的F节点开始,我们先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2, F:2}。我们接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般我们的条件模式基可以不写叶子节点,因此最终的F的条件模式基如下图右所示。

通过它,我们很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},...还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
F挖掘完了,我们开始挖掘D节点。D节点比F节点复杂一些,因为它有两个叶子节点,因此首先得到的FP子树如下图左。我们接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1}此时E节点和G节点由于在条件模式基里面的支持度低于阈值,被我们删除,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。通过它,我们很容易得到D的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。
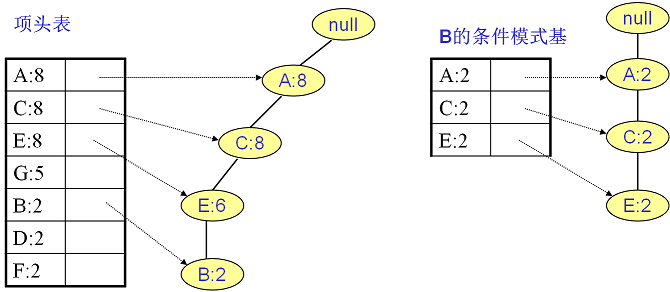
同样的方法可以得到B的条件模式基如下图右边,递归挖掘到B的最大频繁项集为频繁4项集{A:2, C:2, E:2,B:2}。
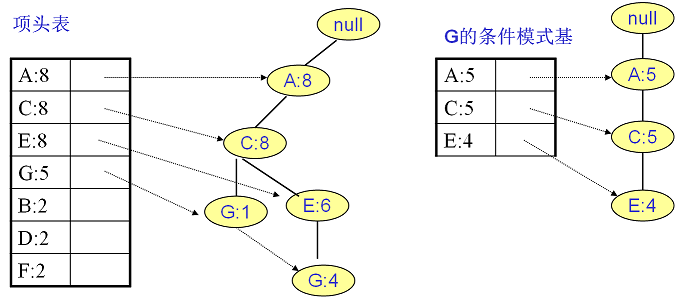
继续挖掘G的频繁项集,挖掘到的G的条件模式基如下图右边,递归挖掘到G的最大频繁项集为频繁4项集{A:5, C:5, E:4,G:4}。
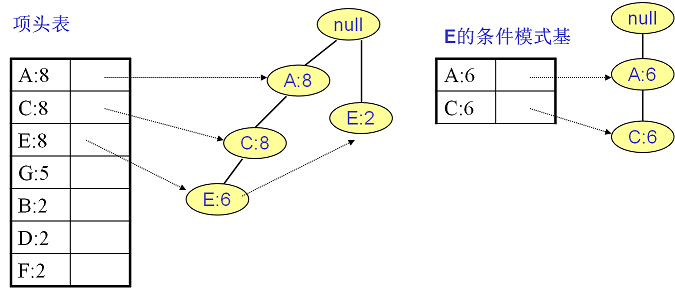
E的条件模式基如下图右边,递归挖掘到E的最大频繁项集为频繁3项集{A:6, C:6, E:6}。
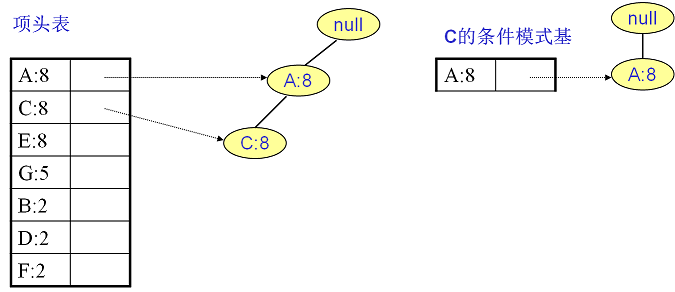
C的条件模式基如下图右边,递归挖掘到C的最大频繁项集为频繁2项集{A:8, C:8}。
至于A,由于它的条件模式基为空,因此可以不用去挖掘了。
至此我们得到了所有的频繁项集,如果我们只是要最大的频繁K项集,从上面的分析可以看到,最大的频繁项集为5项集。包括{A:2, C:2, E:2,B:2,F:2}。
通过上面的流程,相信大家对FP Tree的挖掘频繁项集的过程也很熟悉了。
5. FP Tree算法归纳
这里我们对FP Tree算法流程做一个归纳。FP Tree算法包括三步:
1)扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
2)扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
3)读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
4)从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集。
5)如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。
6. FP tree算法总结
FP Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构,这让我们想起了BIRCH聚类,BIRCH聚类也是巧妙的利用了树结构来提高算法运行速度。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。
在实践中,FP Tree算法是可以用于生产环境的关联算法,而Apriori算法则做为先驱,起着关联算法指明灯的作用。除了FP Tree,像GSP,CBA之类的算法都是Apriori派系的。
看完上述内容,你们掌握FP Tree算法原理是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注行业资讯频道,感谢各位的阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/132969.html
