
本文向您展示了火花连接器阅读器的原理和实践。内容简洁易懂,一定会让你大放异彩。希望通过这篇文章的详细介绍,你能有所收获。
下面主要介绍如何使用火花连接器读取星云图数据。
Spark Connector 简介
Spark Connector是Spark的一个数据连接器,可以用来读写外部数据系统。火花连接器由两部分组成,即阅读器和写入器。本文的重点是Spark Connector Reader,Writer部分将在下一部分与您详细讨论。
Spark Connector Reader 原理
火花连接器阅读器将星云图作为火花的扩展数据源,将星云图中的数据读入DataFrame,然后进行映射、缩小等后续操作。
Spark SQL允许用户自定义数据源,并支持外部数据源的扩展。Spark SQL读取的数据格式是由命名列组织的分布式数据集DataFrame。Spark SQL本身也提供了很多API,方便用户计算和转换DataFrame,可以对多种数据源使用DataFrame接口。
Spark通过org.apache.spark.sql调用外部数据源包首先,我们来了解一下Spark SQL提供的与扩展数据源相关的接口。
00-1010baserelation:指示具有已知模式的元组集。继承基本关系的所有子类必须以结构类型格式生成模式。换句话说,BaseRelation定义了从存储在Spark SQL的DataFrame中的数据源读取的数据的数据格式。
关系提供者:获取参数列表,并根据给定的参数返回一个新的基本关系。
DataSourceRegister:已注册数据源的缩写。使用数据源时,不需要写数据源的完全限定类名,只需要写用户定义的shortName。
Basic Interfaces
RelationProvider:从指定的数据源生成自定义关系。create relationship()根据给定的Params参数生成新的关系。
SchemaRelationProvider:可以基于给定的参数和给定的模式信息生成新的关系。
从数据源扫描后,00-1010 rdd[内部行] :需要构造为RDD[行]。
要定制Spark外部数据源,我们需要根据数据源定制上面的一些方法。
在星云图的Spark Connector中,我们实现了星云图作为Spark SQL的外部数据源,数据可以通过sparkSession.read的形式读取,该函数的类图如下所示:
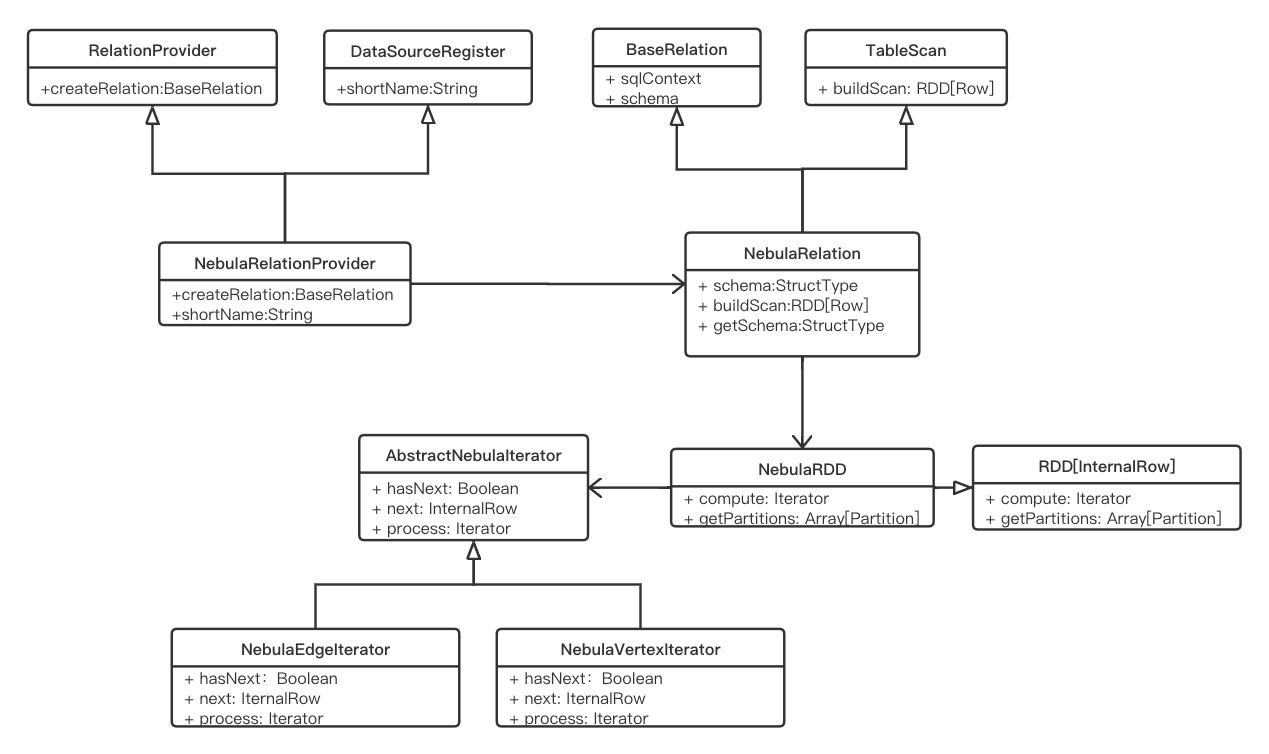

定义数据源星云关系提供者,继承关系提供者进行关系定制,继承数据源注册器进行外部数据源注册。
定义星云关系定义星云图的数据模式和数据转换方法。在getSchema()方法中,连接到星云图的元服务获取与配置的返回字段对应的Schema信息。
定义星云读取星云图数据。compute()方法定义了如何读取星云图数据,主要包括扫描星云图数据,将读取的星云图行数据转换为Spark的InternalRow数据,并用InternalRow形成一行RDD,其中每个in
ternalRow 表示 Nebula Graph 中的一行数据,最终通过分区迭代的形式将 Nebula Graph 所有数据读出组装成最终的 DataFrame 结果数据。
Spark Connector Reader 实践
Spark Connector 的 Reader 功能提供了一个接口供用户编程进行数据读取。一次读取一个点/边类型的数据,读取结果为 DataFrame。
下面开始实践,拉取 GitHub 上 Spark Connector 代码:
git clone -b v1.0 git@github.com:vesoft-inc/nebula-java.git cd nebula-java/tools/nebula-spark mvn clean compile package install -Dgpg.skip -Dmaven.javadoc.skip=true
将编译打成的包 copy 到本地 Maven 库。
应用示例如下:
-
在 mvn 项目的 pom 文件中加入
nebula-spark依赖
<dependency> <groupId>com.vesoft</groupId> <artifactId>nebula-spark</artifactId> <version>1.1.0</version> </dependency>
-
在 Spark 程序中读取 Nebula Graph 数据:
// 读取 Nebula Graph 点数据
val vertexDataset: Dataset[Row] =
spark.read
.nebula("127.0.0.1:45500", "spaceName", "100")
.loadVerticesToDF("tag", "field1,field2")
vertexDataset.show()
// 读取 Nebula Graph 边数据
val edgeDataset: Dataset[Row] =
spark.read
.nebula("127.0.0.1:45500", "spaceName", "100")
.loadEdgesToDF("edge", "*")
edgeDataset.show()
配置说明:
-
nebula(address: String, space: String, partitionNum: String)
address:可以配置多个地址,以英文逗号分割,如“ip1:45500,ip2:45500” space: Nebula Graph 的 graphSpace partitionNum: 设定spark读取Nebula时的partition数,尽量使用创建 Space 时指定的 Nebula Graph 中的 partitionNum,可确保一个Spark的partition读取Nebula Graph一个part的数据。
-
loadVertices(tag: String, fields: String)
tag:Nebula Graph 中点的 Tag fields:该 Tag 中的字段,,多字段名以英文逗号分隔。表示只读取 fields 中的字段,* 表示读取全部字段
-
loadEdges(edge: String, fields: String)
edge:Nebula Graph 中边的 Edge fields:该 Edge 中的字段,多字段名以英文逗号分隔。表示只读取 fields 中的字段,* 表示读取全部字段
上述内容就是Spark Connector Reader 原理与实践是怎样的,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注行业资讯频道。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/133178.html