
本文将详细讲解什么是Spark Join原理,文章内容质量较高,所以边肖将分享给大家参考。希望你看完这篇文章后有所了解。
JoJoining在数据分析中连接两个数据集是非常常见的场景。在Spark的物理规划阶段,Spark的Join Selection类会根据Join提示策略、Join表的大小、Join是否相等、Join涉及的键是否可以排序来选择最终的Join策略。最后,Spark将使用选定的连接策略来执行最终计算。Spark目前支持五种加入策略:
广播散列连接(BHJ)
无序散列连接(SHJ)
无序排序合并连接(SMJ)
洗牌复制嵌套循环连接,也称为笛卡尔乘积连接。
广播嵌套循环连接(BNLJ)
其中,BHJ和SMJ的加盟策略是我们经营Spark工作最常见的。JoinSelection将首先根据连接的键从广播散列连接、随机散列连接和随机排序合并连接中选择一个作为等价连接;如果联接的键是不等联接或未指定联接条件,将选择广播嵌套循环联接或随机复制嵌套循环联接。不同的Join策略在执行效率上有很大的差异,因此需要了解每个Join策略的执行过程和适用条件。
1、Broadcast Hash Join
广播散列连接的实现是将小表的数据广播给Spark的所有执行器。这个广播过程与我们自己广播数据没有什么不同:
使用collect操作符将小表的数据从executor拉至Driver,调用Driver上的sparkContext.broadcast向所有Executor广播,并使用广播数据加入Executor上的大表(实际上是执行映射操作)。
这种连接策略避免了洗牌操作。一般来说,广播散列连接将比其他连接策略执行得更快。
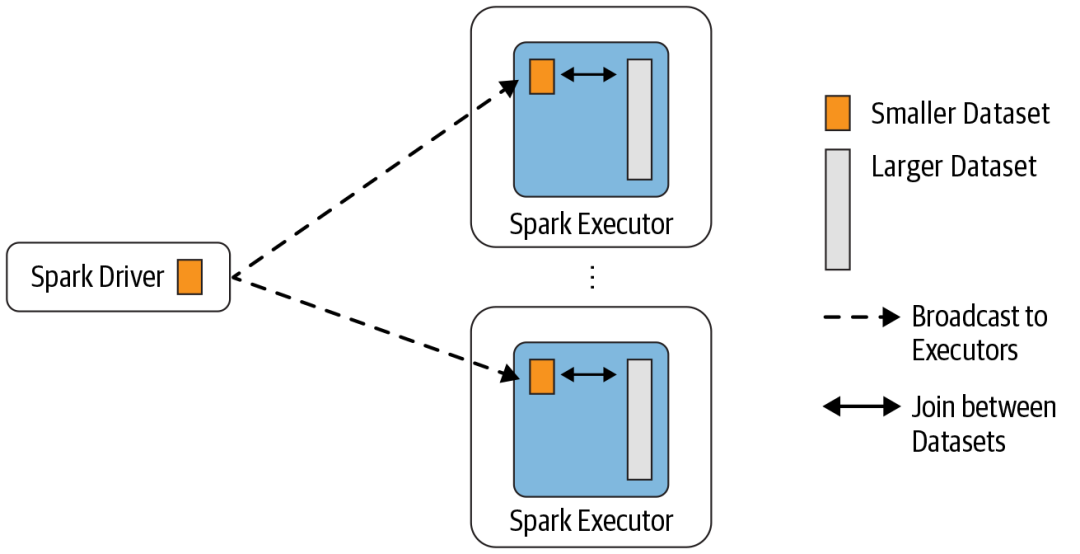

要使用此连接策略,必须满足以下条件:小表的数据必须非常小,这可以通过spark . SQL . autobroadcastjointhreshold参数进行配置。默认值为10MB。如果内存比较大,可以适当提高阈值。将spark . SQL . autobroadcastjointhreshold参数设置为-1,可以关闭。此连接方法只能用于相等联接,参与联接的键不需要可排序。
2、Shuffle Hash Join
当表中的数据很大,不适合广播时,此时可以考虑使用Shuffle Hash Join。混洗散列连接也是连接大表和小表时选择的一种策略。其计算思路是:按照相同的分区算法和分区号(根据参与Join的键进行分区)对大表和小表进行分区,从而保证哈希值相同的数据分布到同一个分区,然后同一个Executor中两个表的哈希值相同的分区可以在本地进行哈希Join。在加入之前,将为小表的分区构建一个哈希映射。Shuffle hash join利用分治的思想,将大问题分解成小问题来解决。
理是什么">
要启用 Shuffle Hash Join 必须满足以下条件: 仅支持等值 Join,不要求参与 Join 的 Keys 可排序 spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为 true,也就是默认情况下选择 Sort Merge Join 小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions(默认值200) 而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是 a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
3、Shuffle Sort Merge Join
前面两种 Join 策略对表的大小都有条件的,如果参与 Join 的表都很大,这时候就得考虑用 Shuffle Sort Merge Join 了。 Shuffle Sort Merge Join 的实现思想: 将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区 对每个分区内的数据进行排序 排序后再对相应的分区内的记录进行连接 无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有序。从 头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join 的稳定性。
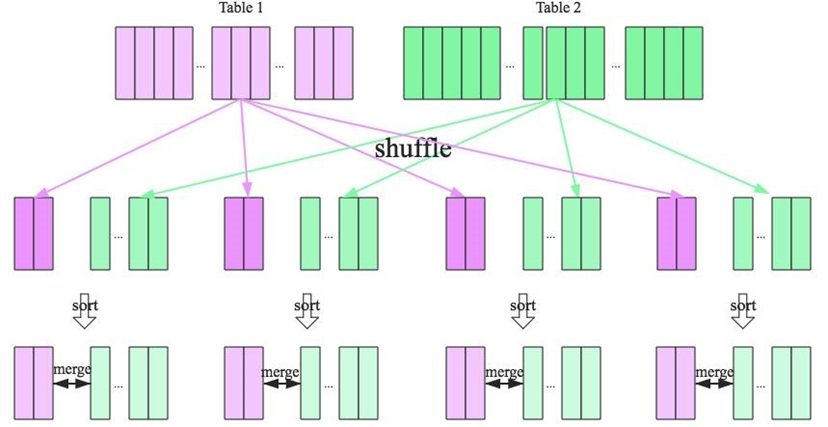
要启用 Shuffle Sort Merge Join 必须满足以下条件:
仅支持等值 Join,并且要求参与 Join 的 Keys 可排序
4、Cartesian product join
如果 Spark 中两张参与 Join 的表没指定连接条件,那么会产生 Cartesian product join,这个 Join 得到的结果其实
就是两张表行数的乘积。
5、Broadcast nested loop join
可以把 Broadcast nested loop join 的执行看做下面的计算:
for record_1 in relation_1:
for record_2 in relation_2:
join condition is executed
可以看出 Broadcast nested loop join 在某些情况会对某张表重复扫描多次,效率非常低下。从名字可以看出,这种
join 会根据相关条件对小表进行广播,以减少表的扫描次数。
Broadcast nested loop join 支持等值和不等值 Join,支持所有的 Join 类型。
关于Spark Join原理是什么就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/133179.html