
如何分析python中的有序变量数据集List,相信很多没有经验的人对此无能为力。为此,本文总结了问题产生的原因和解决方法,希望大家可以通过这篇文章来解决这个问题。
列表是有序的变量数据集。有序意味着列表中的数据将按照存放的顺序存储。可变意味着列表的长度会随着数据的增加而变长,而不是固定的大小。
作为最常用的基础数据结构,列表有什么用?例如,如果我们想动态访问中国所有的省、市、自治区,我们可以使用列表。让我们先拯救几个省份:
首先打开IDLE。

然后进入

省份=['浙江','江苏','上海'
创建一个名为“提供商”的新列表,其初始值为“浙江”、“江苏”和“上海”。该列表包含三个元素。直接在IDLE中输入Providers将显示列表内容。
Len(省份)可以检查列表中有多少元素。
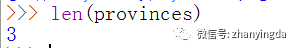
如果我们必须增加其他省份呢?
您可以使用列表附带的append()方法:
省份.附加(“广东省”)

列表底部自动添加广东省,表示列表有序,将按照列表数据添加的顺序排列。
如果要删除指定的元素,可以使用remove()
省份.删除('上海')

如果要从特定索引中删除数据,可以使用pop()函数等。什么是指数?所谓索引就是数据在列表中的位置,索引从0开始计数。

我们删除索引为1的数据。

江苏已删除。细心的同学可能已经发现,删除pop(1)时会显示删除值‘江苏’,因为pop()方法会在删除的同时返回删除的数据,字面意思就是这个数据弹出来了。
如果pop()不写索引值会怎么样?

是的,如果没有写入索引值,最后一个元素会弹出。
现在列表里只剩下一个元素‘浙江’。数据很匆忙。先补充一些数据。我们可以使用append()方法。这是个好主意,但我们还有其他快速方法:

extend()方法在原始列表之后添加一个新列表。
如果我们想在指定的位置添加元素呢?

Insert(1,'江苏')在第一个索引位置插入'江苏'元素,第一个索引位置的原始'广东'和后面的所有元素向后移动一个位置。
如果我们再插入一个‘江苏’呢?列表允许重复数据吗?

这个列表最初允许重复数据。是否存在不允许重复数据的数据结构?
看完以上,你掌握了python中如何分析有序变量数据集List的方法了吗?如果您想学习更多技能或了解更多相关内容,请关注行业资讯频道,感谢您的阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/134039.html