
我相信很多没有经验的人对于如何理解python的merge一窍不通。为此,本文总结了问题产生的原因和解决方法,希望大家可以通过本文来解决这个问题。
merge
pandas的merge方法提供了类似SQL的内存链接操作,官网文档提到其性能比其他开源语言的数据操作(如R)更高效。
这里可以看到与SQL语句的比较。
合并参数
On:列名,联接用来对齐的列的名称。使用此参数时,请确保左表和右表使用的列具有相同的列名。
Left_on:左表中对齐的列可以是列名,也可以是与dataframe长度相同的数组。
Right_on:右表中对齐的列可以是列名,也可以是与dataframe长度相同的数组。
Left _ index/right _ index3360如果为True,闹鬼会将索引作为对齐的关键。
如何:数据融合的方法。
排序:按照字典顺序中数据框合并的关键字进行排序。默认情况下,设置false可以提高性能。
合并的默认合并方法:
合并用于基于索引对索引和列对索引的表内合并,但默认为基于索引的合并。2
1.1 复合key的合并方法
使用合并时,可以选择多个键作为复合来对齐和合并。1
1.1.1 通过on指定数据合并对齐的列
In[41]:left=pd。DataFrame({'key1':['K0 ',' K0 ',' K1 ',' K2 '),
.'key2':['K0 ',' K1 ',' K0 ',' K1'],
.'A':['A0 ',' A1 ',' A2 ',' A3'],
.'B':['B0 ',' B1 ',' B2 ',' B3']})
.
在[42]:right=pd中。DataFrame({'key1':['K0 ',' K1 ',' K1 ',' K2 '),
.'key2':['K0 ',' K0 ',' K0 ',' K0'],
.“C”:[“C0”,“C1”,“C2”,“C3”],
.'D':['D0 ',' D1 ',' D2 ',' D3']})
.
In[43]:result=pd.merge(左,右,on=['key1 ',' key 2 '])1234567891011121312345678910111213

如果没有指定how,默认情况下将使用内部方法。
如何的方法是:
left
仅保留左表中的所有数据。
in[44]: result=PD . merge(left,right,how='left ',on=['key1 ',' key 2 '])11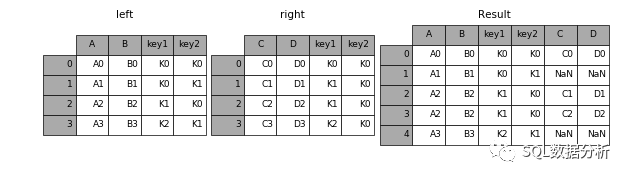
right
仅保留右表中的所有数据。
In[45]:result=pd.merge(左,右,how='right ',on=['key1 ',' key 2 '])11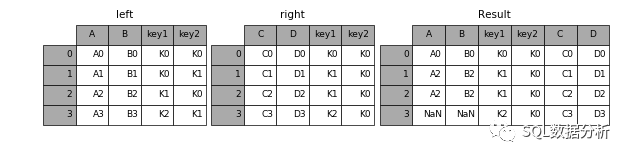
outer
保留两个表的所有信息。
In[46]:result=pd.merge(左,右,how='outer ',on=['key1 ',' key 2 '])11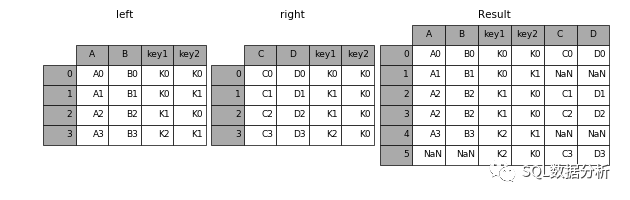
00-1010仅保留两个表中的公共信息。
In[47]:result=pd.merge(左,右,how='inner ',on=['key1 ',' key 2 '])11
思考:如果左右键值对名称不一致,应该如何关联?
看完以上内容,你掌握了如何理解python的merge了吗?如果您想学习更多技能或了解更多相关内容,请关注行业资讯频道,感谢您的阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/134043.html