
本文介绍了如何解决数十亿用户的分布式数据库数据存储问题。内容非常详细,有兴趣的朋友可以参考一下,希望对你有帮助。
一、MySQL复制
1.MySQL的主从复制
MySQL的主从复制就是将MySQL主数据库中的数据复制到从数据库中。
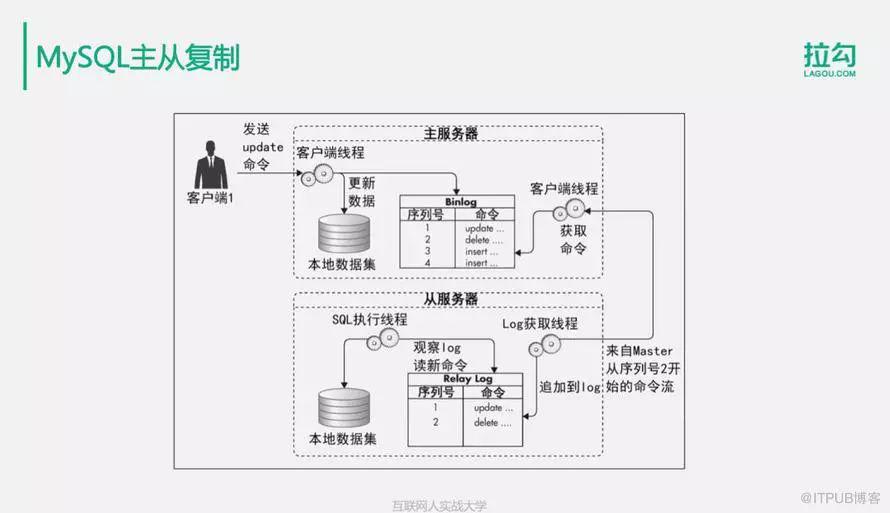
主要目的是实现数据库读写分离,写操作访问主数据库,读操作访问从数据库,使数据库具有更强的访问负载能力,支持更多用户的访问。
它的主要复制原理是:当应用客户端向数据库发送更新命令时,数据库会将这个更新命令同步记录在Binlog中,然后另一个线程从Binlog中读取这个日志,再通过远程通信复制到从服务器。从服务器获取此更新日志后,它将被添加到自己的中继日志中,然后另一个SQL执行线程将从中继日志中读取此新日志,并在本地数据库中重新读取它。
这样,当客户端应用程序执行更新命令时,该命令将在主数据库和从数据库上同步执行,从而实现主数据库到从数据库的复制,并在从数据库和主数据库之间保持相同的数据。
2.MySQL的一主多从复制
MySQL的主从复制是一种数据同步机制,它不仅可以将数据从一个主数据库同步复制到一个从数据库,还可以将数据从一个主数据库同步复制到多个从数据库,这就是MySQL所谓的主从复制。
多个从数据库连接到主数据库后,主数据库上的Binlog日志会同步复制到多个从数据库。通过执行日志,每个从数据库的数据与主数据库的数据一致。这里的数据更新操作代表所有数据库的更新操作。除了SELECT等查询读操作,其他的INSERT、DELETE、update等DML写操作,CREATE TABLE、DROPT ABLE、ALTER TABLE等DDL操作也可以同步复制到从数据库。
3.一主多从复制的优点
主从复制有四大优势,即负载分担、专机使用、易冷待机和高可用性。
a.分摊负载
在多个从属数据库上分配只读操作,从而将负载分配给多个服务器。
b.专机专用
不同的从属服务器可以用于不同类型的查询。
c.便于进行冷备
即使数据库由一个主服务器和多个从服务器复制,在某些极端情况下。它还可能导致整个数据中心的数据服务器丢失。所以一般来说很多公司都会对数据做冷备份,但是冷备份的难点之一就是如果正在写入数据库,那么冷备份数据可能不完整,数据文件可能处于损坏状态。使用一个主设备和多个从设备可以实现零停机备份。只需关闭数据的数据复制过程,文件就会关闭,然后复制数据文件,复制完成后再重新打开数据复制。
d.高可用
如果一台服务器出了故障,只要你不向这台服务器发送请求,就不会有问题。当此服务器恢复时,向此服务器重新发送请求。因此,在一个主服务器和多个从服务器的情况下,一个从服务器的停机时间是不可用的,对整个系统的影响非常小。
4.MySQL的主主复制
然而,一个主服务器和多个从服务器只能在从服务器上实现这些优势。当主数据库宕机不可用时,数据无法写入,因为数据无法写入从服务器,而从服务器是只读的。
为了解决主服务器的可用性问题,我们可以使用MySQL的主主复制方案。所谓的主-主复制方案是指两台服务器都被视为主服务器,在任何一台服务器上接收到的写操作都会被复制到另一台服务器上。
如上图主副本示意图所示,当客户端程序更新主服务器A的数据时,主服务器A会将更新操作写入Binlog日志日志。然后Binlog会将数据日志同步到主服务器B,写入主服务器的Relay日志,然后持有Relay日志,在Relay日志中获取更新日志,执行SQL操作写入数据库服务器B的本地数据库,服务器B上的更新也通过Binlog复制到服务器A上的Relay日志,然后通过Relay日志将数据更新到服务器A。
这样,服务器A或B中任何一台接收到数据写操作的服务器都会同步更新到另一台服务器上,从而实现数据库的主副本。主复制可以提高系统的写可用性,实现写操作的高可用性。
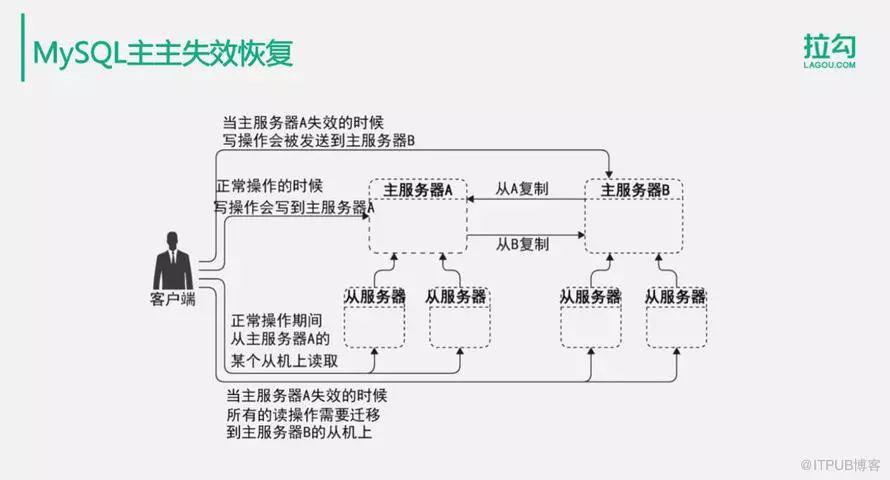
5.MySQL的主主失效恢复
使用MySQL服务器实现主从复制时,如何处理数据库服务器的故障?
p>
正常情况下用户会写入到主服务器A中,然后数据从A复制到主服务器B上。当主服务器A失效的时候,写操作会被发送到主服务器B中去,数据从B服务器复制到A服务器。

主主失效的维护过程如下:
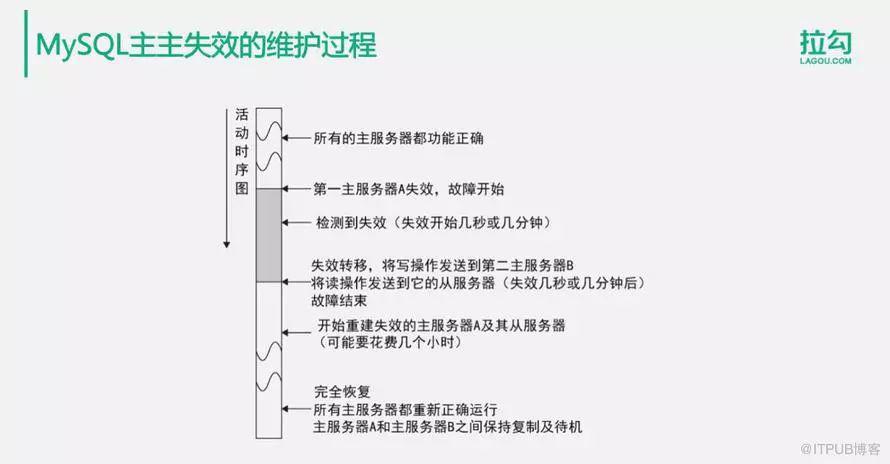
最开始的时候,所有的主服务器都可以正常使用,当主服务器A失效的时候,进入故障状态,应用程序检测到主服务器A失效,检测到这个失效可能需要几秒钟或者几分钟的时间,然后应用程序需要进行失效转移,将写操作发送到备份主服务器B上面去,将读操作发送到B服务器对应的从服务器上面去。
一段时间后故障结束,A服务器需要重建失效期间丢失的数据,也就是把自己当作从服务器从B服务器上面去同步数据。同步完成后系统才能恢复正常。这个时候B服务器是用户的主要访问服务器,A服务器当作备份服务器。
5.MySQL复制注意事项
使用MySQL进行主主复制的时候需要注意的事项如下:
a.不要对两个数据库同时进行数据写操作,因为这种情况会导致数据冲突。
b.复制只是增加了数据的读并发处理能力,并没有增加写并发的能力和系统存储能力。
c.更新数据表的结构会导致巨大的同步延迟。
需要更新表结构的操作,不要写入到到Binlog中,要关闭更新表结构的Binlog。如果要对表结构进行更新,应该由运维工程师DBA对所有主从数据库分别手工进行数据表结构的更新操作。
二、数据分片
数据复制只能提高数据读并发操作能力,并不能提高数据写操作并发的能力以及数据整个的存储容量,也就是并不能提高数据库总存储记录数。如果我们数据库的写操作也有大量的并发请求需要满足,或者是我们的数据表特别大,单一的服务器甚至连一张表都无法存储。解决方案就是数据分片。
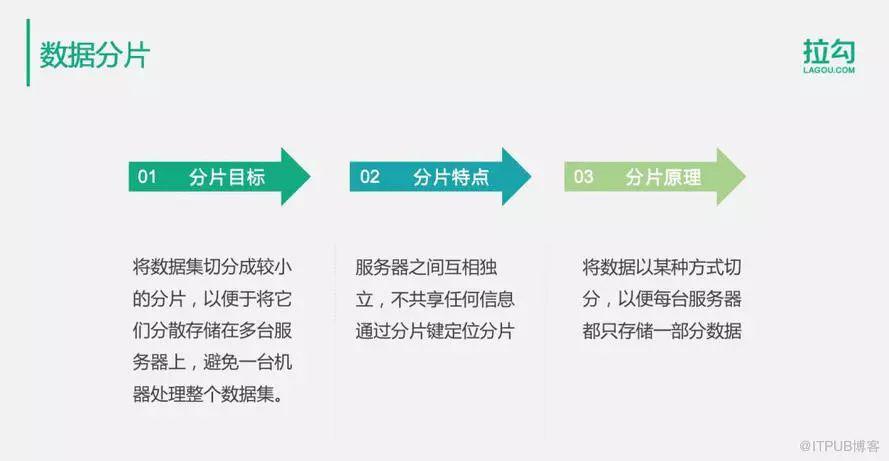
1.数据分片介绍
a.主要目标:将一张数据表切分成较小的片,不同的片存储到不同的服务器上面去,通过分片的方式使用多台服务器存储一张数据表,避免一台服务器记录存储处理整张数据表带来的存储及访问压力。
b.主要特点:数据库服务器之间互相独立,不共享任何信息,即使有部分服务器故障,也不影响整个系统的可用性。第二个特点是通过分片键定位分片,也就是说一个分片存储到哪个服务器上面去,到哪个服服务器上面去查找,是通过分片键进行路由分区算法计算出来的。在SQL语句里面,只要包含分片键,就可以访问特定的服务器,而不需要连接所有的服务器,跟其他的服务器进行通信。
.主要原理:将数据以某种方式进行切分,通常就是用刚才提到的分片键的路由算法。通过分片键,根据某种路由算法进行计算,使每台服务器都只存储一部分数据。
2.硬编码实现数据分片
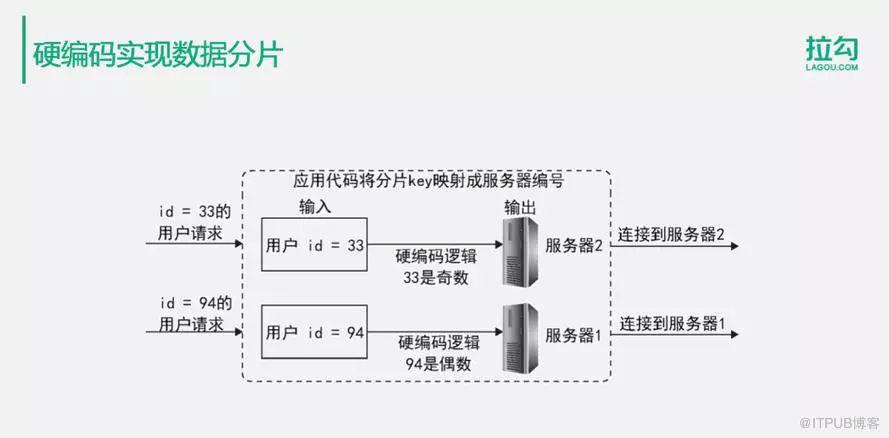
如图例子,通过应用程序硬编码的方式实现数据分片。假设我们的数据库将数据表根据用户ID进行分片,分片的逻辑是用户ID为奇数的数据存储在服务器2中,用户ID为偶数的数据存储在服务器1中。那么,应用程序在编码的时候,就可以直接通过用户ID进行哈希计算,通常是余数计算。如果余数为奇数就连接到服务器2上,如果余数为偶数,就连接到服务器1上,这样就实现了一张用户表分片在两个服务器上。
这种硬编码主要的缺点在于,数据库的分片逻辑是应用程序自身实现的,应用程序需要耦合数据库分片逻辑,不利于应用程序的维护和扩展。一个简单的解决办法就是将映射关系存储在外面。
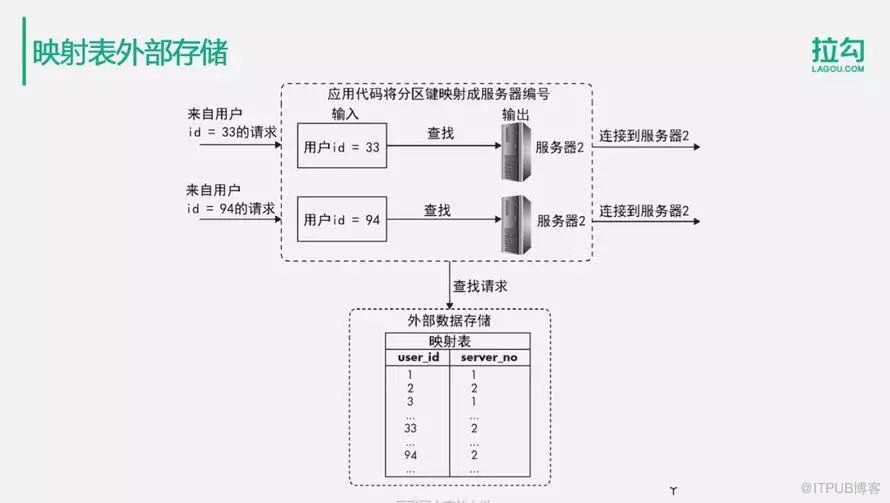
3.映射表外部存储
应用程序在连接数据库进行SQL操作的时候,通过查找外部的数据存储查询自己应该连接到哪台服务器上面去,然后根据返回的服务器的编号,连接对应的服务器执行相应的操作。在这个例子中,用户ID=33查是2,用户ID=94查也是2,它们根据查找到的用户服务器的编号,连接对应的服务器,将数据写入到对应的服务器分片中。
4.数据分片的挑战及解决方案
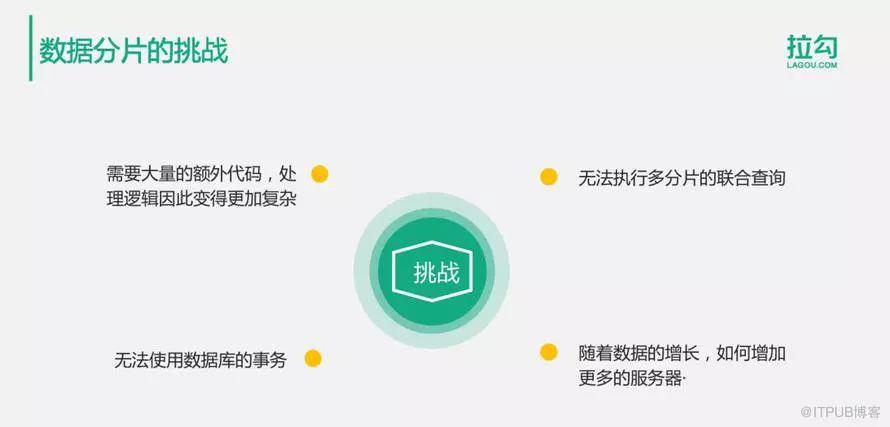
数据库分片面临如图的挑战:
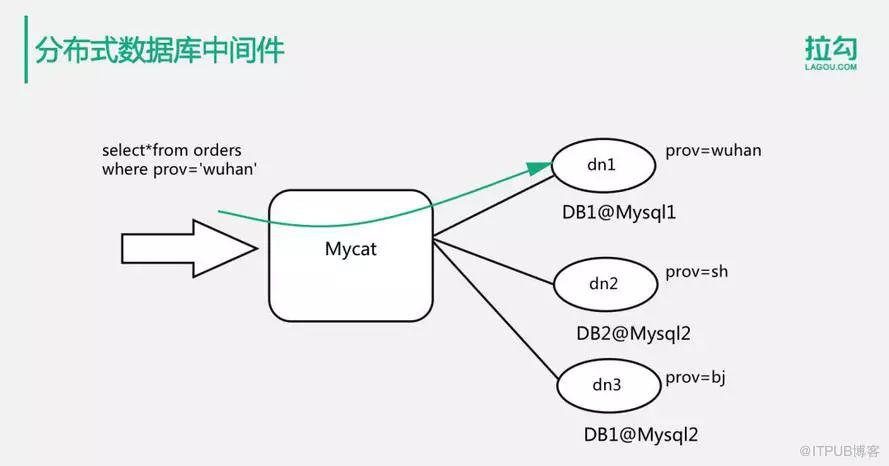
现在有一些专门的分布式数据库中间件来解决上述这些问题,比较知名的有Mycat。Mycat是一个专门的分布式数据库中间件,应用程序像连接数据库一样的连接Mycat,而数据分片的操作完全交给了Mycat去完成。
如下这个例子中,有3个分片数据库服务器,数据库服务器dn1、dn2和dn3,它们的分片规则是根据prov字段进行分片。那么,当我们执行一个查询操作”select * from orders where prov=’wuhan’“的时候,Mycat会根据分片规则将这条SQL操作路由到dn1这个服务器节点上。dn1执行数据查询操作返回结果后,Mycat再返回给应用程序。通过使用Mycat这样的分布式数据库中间件,应用程序可以透明的无感知的使用分片数据库。同时,Mycat还一定程度上支持分片数据库的联合join查询以及数据库事务。
5.分片数据库扩容伸缩
一开始,数据量还不是太多,两个数据库服务器就够了。但是随着数据的不断增长,可能需要增加第三个第四个第五个甚至更多的服务器。在增加服务器的过程中,分片规则需要改变。分片规则改变后,以前写入到原来的数据库中的数据,根据新的分片规则,可能要访问新的服务器,所以还需要进行数据迁移。
不管是更改路由算法规则,还是进行数据迁移,都是一些比较麻烦和复杂的事情。因此在实践中通常的做法是数据分片使用逻辑数据库,也就是说一开始虽然只需要两个服务器就可以完成数据分片存储,但是依然在逻辑上把它切分成多个逻辑数据库。具体的操作办法,本文不用大篇幅进行阐述了。
三、数据库部署方案
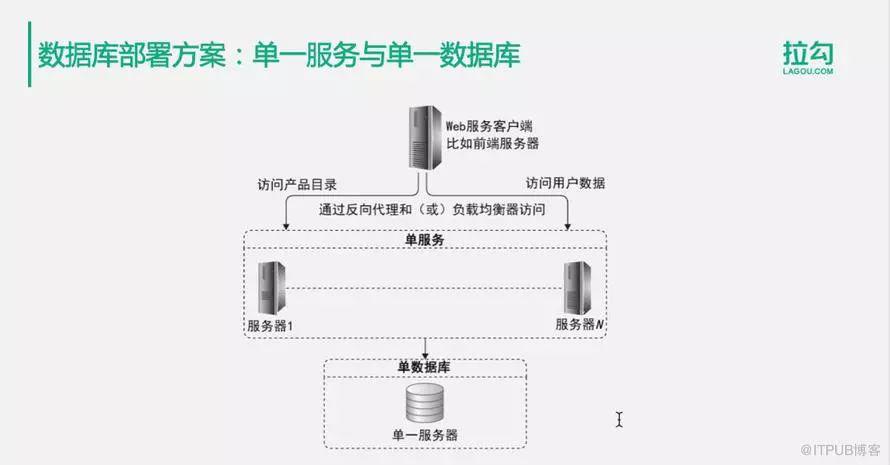
1.单一服务和单一数据库
这是最简单的部署方案。应用服务器可能有多个,但是它们完成的功能是单一的功能。多个完成单一功能的服务器,通过负载均衡对外提供服务。它们只连一台单一数据库服务器,这是应用系统早期用户量比较低的时候的一种架构方法。
2.主从复制实现伸缩
如果对系统的可用性和对数据库的访问性能提出更高要求的时候,就可以通过数据库的主从复制进行初步的伸缩。通过主从复制,实现一主多从。应用服务器的写操作连接主数据库,读操作从从服务器上进行读取。
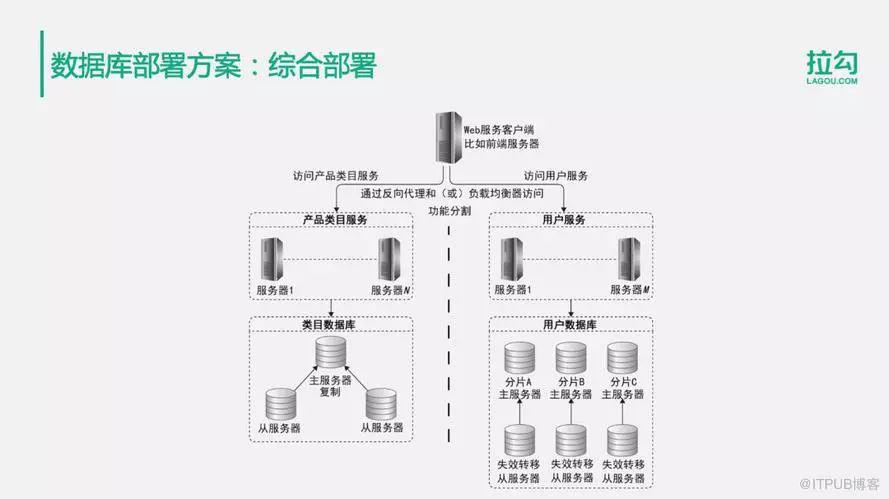
3.两个Web服务及两个数据库
随着业务更加复杂,为了提供更高的数据库处理能力,可以进行数据的业务分库。数据的业务分库是一种逻辑上的,是基于功能的一种分割,将不同用途的数据表存储在不同的物理数据库上面去。
在这个例子中,有产品类目服务和用户服务,两个应用服务器集群,对应的也将数据库也拆分成两个,一个叫做类目数据库,一个叫做用户数据库。每个数据库依然使用主从复制。通过业务分库的方式,在同一个系统中,提供了更多的数据库存储,同时也就提供了更强大的数据访问能力,同时也使系统变得更加简单,系统的耦合变得更低。
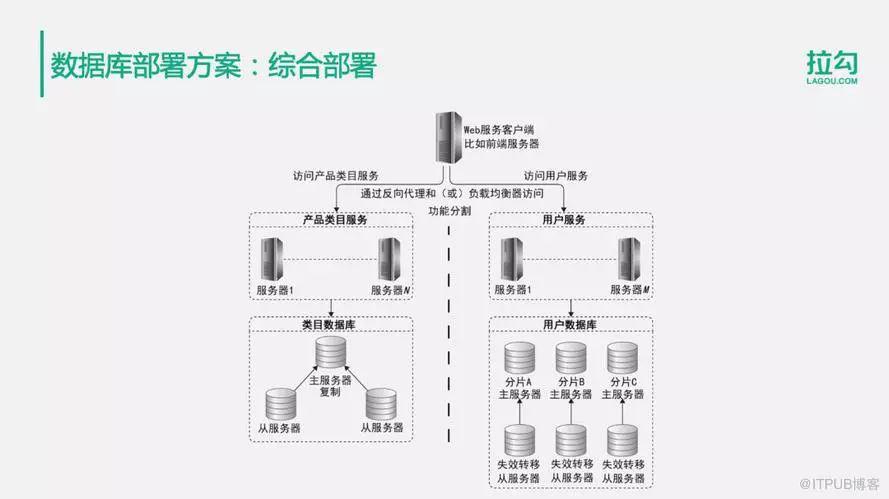
4.综合部署方案
根据不同数据的访问特点,使用不同的解决方案进行应对。比如说类目数据库,也许通过主从复制就能够满足所有的访问要求。但是如果用户量特别大,进行主从复制或主主复制,还是不能够满足数据存储以及写操作的访问压力,这时候就就可以对用户数据库进行数据分片存储了。同时每个分片数据库也使用主从复制的方式进行部署。
关于如何解决亿级用户的分布式数据库数据存储问题就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/138390.html