
本文主要给大家展示“Hadoop的基础知识有哪些”,简单易懂,条理清晰,希望能帮你解决疑惑。让边肖带领大家学习《Hadoop的基础知识是什么》一文。
Hadoop概述
Hadoop这个词本身并没有什么特殊的含义,只是它的作者Doug Cutting的孩子的一个棕色大象玩具的名字。
Hadoop是一个高度可靠、可扩展和分布式的开源软件框架。它使我们能够使用简单的编程模型来处理存储在集群中的大型数据集。
Hadoop是Apache Foundation的开源项目,是一个提供分布式存储和分布式计算功能的基础设施平台。它可以应用于企业的数据存储、日志分析、商业智能、数据挖掘等。
00-1010 1.Hadoop中包含的模块:
Hadoop common:提供一些通用功能来支持其他hadoop模块。
Hadoop Distributed File System:分布式文件系统,简称HDFS。主要用于数据存储和提供对应用数据的高吞吐量访问。
Hadoop Yarn:作业调度和集群资源管理框架。
基于Hadoop MapReduce:纱线的计算框架,可用于并行处理大型数据集。
2.HDFS:
HDFS是谷歌GFS的开源实现,具有扩展性,容错性和海量数据存储:的特点
扩展性主要是指在当前集群中很容易添加一台或多台机器来扩展计算资源。
容错主要指其多副本存储机制。HDFS将文件切割成固定大小的块(默认值为128兆字节),并将它们存储在多台机器上的多个副本中。当其中一台机器出现故障时,仍有其他副本供我们使用。但这种容错性并不是绝对的。当所有节点都出现故障时,文件会丢失,但概率很小。
海量数据存储:多台机器组成一个集群,可以比单台机器存储更多的数据。这也是Hadoop解决的最重要的问题之一。
数据分割、多副本、容错等机制都是Hadoop设计的,对用户透明,用户不需要关系细节。只能按照单机文件的操作方式来操作分布式文件。比如上传、查看、下载文件。
多副本存储的示例:
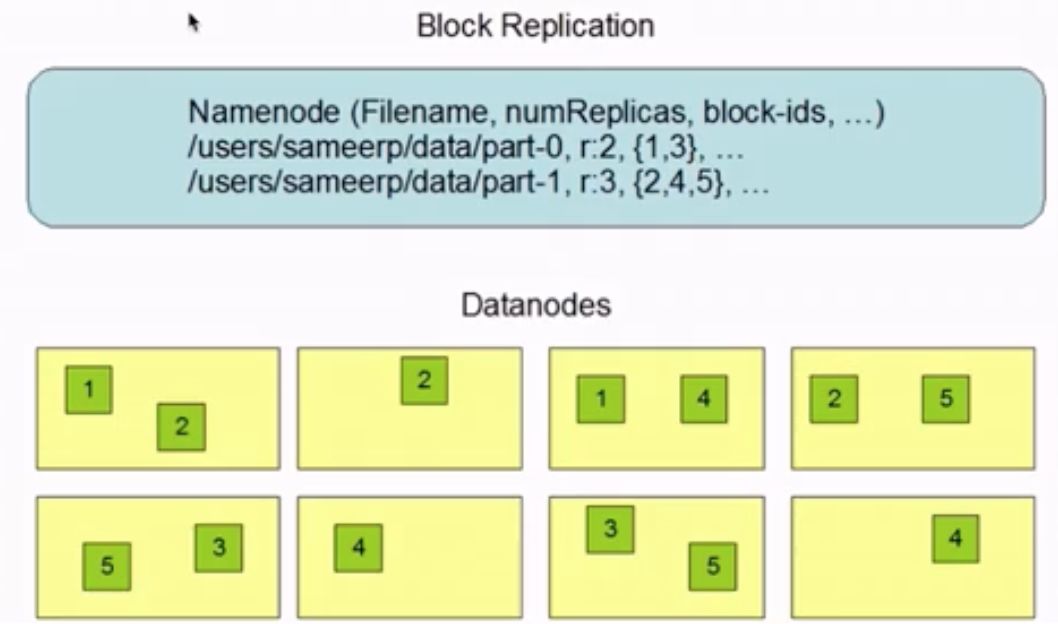

以part-1为例,说明了HDFS多副本存储的示意图。它分为三个块,block_id分别为2,4,5,复制系数为3。可以看到,在DataNode上,2、4和5都存储在三个节点中,因此当其中一个节点出现故障时,文件仍然可以使用。block_id存在的必要性在于,当用户需要操作文件时,可以依次“组合”对应的块。
3.纱线:
纱的全名是另一个资源协商者,负责整个集群资源的管理和调度。例如,为每个作业分配CPU和内存是由纱线管理的。它的特点是扩展性,容错性和多框架资源统一调度.
可伸缩性与HDFS的可伸缩性类似,纱线可以轻松扩展其计算资源。
容错主要是指出了问题,纱线会重试一定次数。
多框架资源是统一调度的,这比hadoop1.0版本有优势。与hadoop1.0不同,它只支持MapReduce作业。不同类型的工作可以在纱线上进行。如下图所示,许多应用程序可以在纱线上运行,这是由纱线统一调度的。
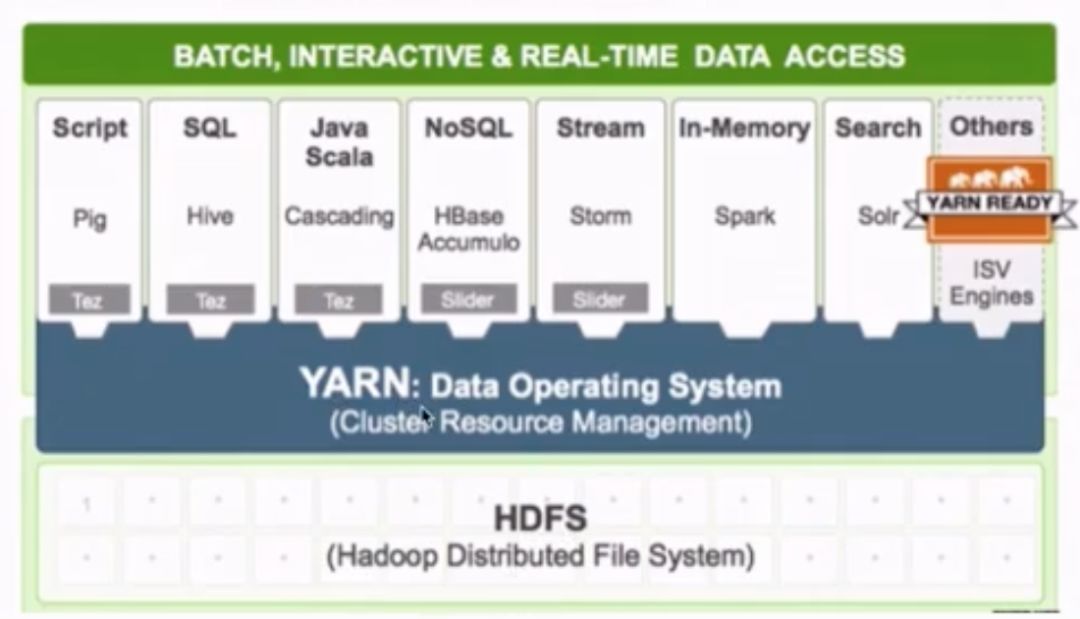
运行在YARN 4上的各种应用程序。mapreduce:
是分布式计算框架,是GoogleMapReduce的克隆版。类似于HDFS和纱,它也有扩展性和容错.
性的特点,还将具有海量数据离线处理的特点:能够处理的数据量大,但并不是实时处理,具有较大的延时性。
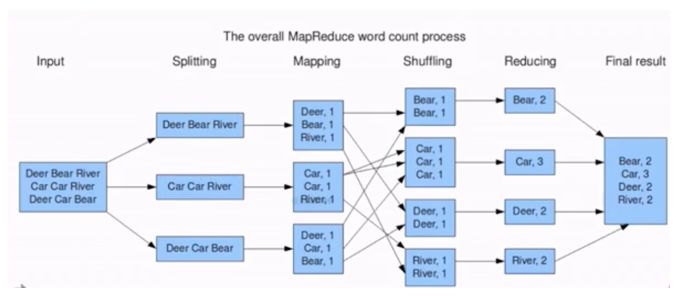
WordCount的MapReduce流程如图所示,主要分为Map和Reduce两个过程。Map阶段做映射,对所有输入的单词赋值为1,Reduce阶段做汇总,相同的单词分发到一个节点上并进行求和,最终就可以统计出单词的个数。
hadoop的优势
hadoop的优势主要体现在高可靠性,高扩展性等方面。
高可靠性是指多副本的存储机制和失败作业的重新调度计算。
高扩展性是指资源不够时很容易直接扩展机器。一个集群可以包含数以千计的节点。
其他优势还表现在:hadoop完全可以部署在普通廉价的机器上,成本低。同时它具有成熟的生态圈和开源社区。
狭义hadoop VS 广义hadoop:
狭义hadoop:指一个用于大数据分布式存储(HDFS),分布式计算(MapReduce)和资源调度(YARN)的平台,这三样只能用来做离线批处理,不能用于实时处理,因此才需要生态系统的其他的组件。
广义的hadoop:指的是hadoop的生态系统,即其他各种组件在内的一整套软件。hadoop生态系统是一个很庞大的概念,hadoop只是其中最重要最基础的部分,生态系统的每一个子系统只结局的某一个特定的问题域。不是一个全能系统,而是多个小而精的系统。
hadoop生态系统
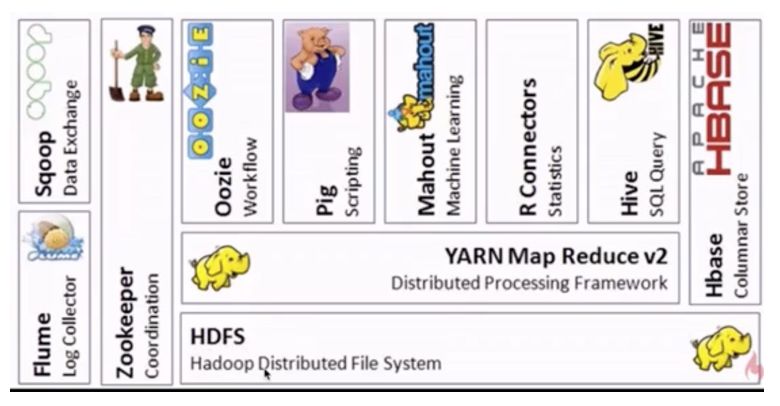
上图是hadoop生态系统的一个构成。HDFS是基础的文件系统,用来存储数据,多副本,高容错。MapReduce用来进行并行计算,它运行在Yarn之上。这是前文提到过的三大核心组件,下面我们简要介绍图中的其他部分。
由于MapReduce的学习成本相对较高,这样就诞生了一些其他框架。
Hive 处理的是海量结构化日志数据的统计问题。它定义了一种类似SQL的语言Hive QL,借助于hive引擎能将其转换为MapReduce作业并提交到集群上进行运算。hive适用于离线处理。相比之下,SQL的门槛就低得多
Mahout是一个机器学习算法库,实现了很多数据挖掘的经典算法,帮助用户很方便地创建应用程序。
Pig可以将脚本任务转换为MapReduce作业,同样是适用于离线分析。
Oozie是一个工作流调度引擎,用来处理具有依赖关系的作业调度。类似的框架有Azkaban,airflow等。
Zookeeper:分布式协调服务,“动物园管理员”角色,是一个对集群服务进行管理的框架,如维护故障切换等。
Flume:日志收集框架。将多种应用服务器上的日志,统一收集到HDFS上,这样就可以使用hadoop进行处理
Sqoop:提供关系型数据库与HDFS数据相互传输的功能。
Hbase:面向列存储的数据库。适用于实时快速查询的场景。
除此之外,还有spark,kafka,flink,redis等新兴的一些实用框架。
reference:https://blog.csdn.net/zcb_data/article/details/80402411
Hadoop生态系统的特点:
-
开源,社区高活跃
开源意味着源码可获取,可以直接基于源码进行改造实现个性化需求。社区活跃高意味着迭代更新快,维护的人多。
-
囊括了大数据处理的方方面面
-
具有成熟的生态圈。
hadoop发行版本的选择
-
Apache hadoop:解决了单个框架的额问题,综合起来使用会有jar包冲突,不适合于生产环境。
-
CDH:Cloudera Distributed Hadoop。商业版本。使用Cloudera Manager对集群进行管理,通过浏览器,不需要通过linux就可以安装,与spark结合的很好。没有jar包冲突的问题。但Cloudera Manager不开源,企业版收费。
CDH的下载地址:http://archive.cloudera.com/cdh6/cdh/5/
-
HDP:Hortonworks Data Platform。商业版本之一,使用Ambari进行统一管理,对服务的用户收费。
以上是“Hadoop基础知识有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注行业资讯频道!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/139129.html