
本文主要介绍“Hadoop、Lambda和kappa有什么用”。日常操作中,相信很多人对Hadoop、Lambda、kappa的使用都有疑问。边肖查阅了各种资料,整理出简单易用的操作方法,希望能帮助大家解答“Hadoop、Lambda、kappa有什么用”的疑惑!接下来,请和边肖一起学习!
随着互联网的快速发展,越来越多的人涌入互联网,互联网从此进入了大数据时代。大数据时代之后,云计算、人工智能、物联网和5G技术的发展,将大数据的发展推向了高潮。
数据已经从最初的信息逐步演变为数据产品和数据资产。关于数据处理技术,包括数据库、数据集市、数据仓库、数据湖和数据中心,每一个数据处理的演进都代表着业务需求的变化趋势和技术的演进。
除了数据处理方法的演进,数据处理的基本度量也在不断演进,包括Hadoop、Lambda和Kappa。这三种数据处理思路都是为了解决数据处理过程中遇到的问题而产生的,每个解决方案都有对应的场景,没有过时的理论。
第一代基础设施:.以Hadoop为代表的离线数据处理早期互联网还在红海,大家对数据分析的要求不高,主要是做报表和支持决策,相应的离线数据分析方案应运而生。
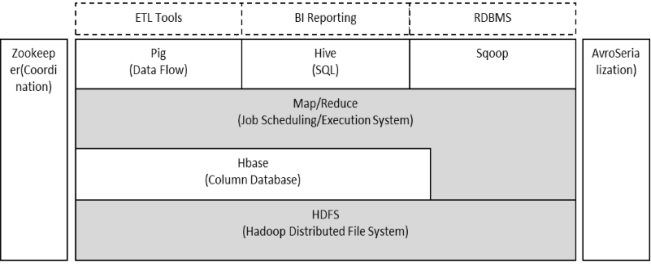
Hadoop提供了一套完整的解决方案。底层采用HDFS分布式文件系统作为数据存储,所有数据采用MapReduce计算模型进行处理(数据计算任务分为Map和Reduce两个过程,Map进行一次处理生成中间结果,Reduce进行二次处理,中间结果进行分析生成最终数据)。为了简化用户的成本,Hadoop在MapReduce的基础上提供了Pig和HIve平台。Pig支持海量数据并行计算,并提供向上层报告和导入关系数据库的接口。HIve基于SQL语句错误地分析数据,降低了产品和操作人员的使用成本。整个Hadoop数据处理系统使用Zookeeper来协调任务节点的管理和资源的分配,保证系统的正常运行。

第二代基础设施:.以Lambda为代表的批量流的数据处理随着互联网用户的涌入,很多企业开始涌入互联网,对数据处理和数据分析的要求也越来越高。
Hadoop系统在运行大量数据时,耗时会越来越长,已经不能满足一些需要实时分析处理的场景(比如淘宝会动态推荐产品),于是出现了Flink、Storm、SparkStreaming等新型的流媒体计算引擎。开始崭露头角。提出了新的大数据处理方法。只有当流处理和批处理一起使用时,才能满足大多数使用场景。因此,提出了lambda架构。
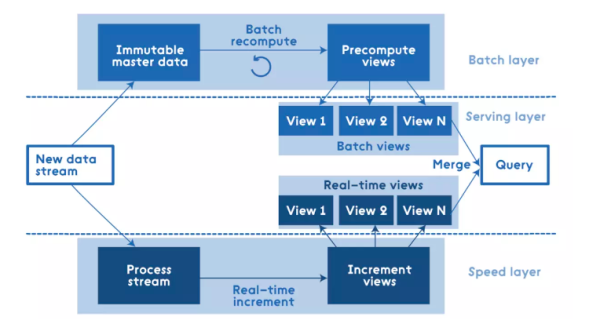
Lambda架构通过将数据分解为三层来解决不同数据集中的数据需求:ServingLayer、SpeedLayer和BatchLayer。批处理层主要处理离线数据,对访问的数据进行预处理和存储。查询时,直接对预处理后的结果进行查询,无需完整计算,最后提供给View层的服务。在速度层,主要处理实时增量数据。每当新数据到来时,视图层就会不断更新并提供给服务。在服务层,主要是响应用户的请求,根据用户的需求将批处理层和速度层的数据收集在一起,得到最终的数据集。Lambda架构的优点是将流处理和批处理分开,很好地结合了实时计算和流计算的优点,架构稳定,实时计算成本可控,提高了整个系统的容错性,降低了复杂度。缺点是离线数据和实时数据难以保证数据一致性,开发人员需要维护两个系统。
以第三代基础设施:. Kappa为代表的集成流批处理数据处理基于Lambda架构的流批处理分离解决了数据一致性问题,提高了效率,但也相应增加了系统的复杂度。因此,预计将产生一个流批的系统解决方案,即Kappa架构。利用流计算的分布式特性,增加流计算的并发性,扩大流数据的时间窗口,统一批处理和流处理数据。
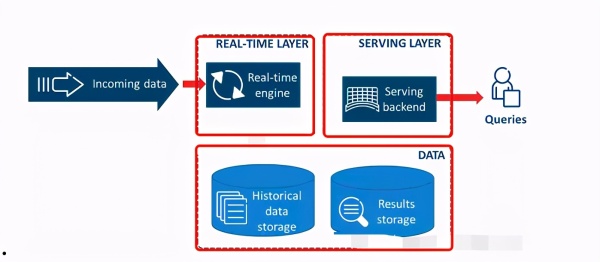
Kappa架构在Lambda架构的基础上删除了Batch层,所有数据通过流处理实时计算。经过计算,可以直接供业务层使用,也可以放在数据湖里进行离线分析。Kappa架构的优点是开发者只需要维护实时处理模块,无需离线实时数据合并,缺点是实时处理可能存在信息丢失。
整个互联网大数据处理基础设施体系,从Hadoop到Lambda再到Kappa,涵盖了业务所需的各种数据处理方式,大数据平台已经成为全数据处理平台。基于这些基础设施,在云计算基础设施的保障下,我们可以有数据集市、数据仓库、数据湖、数据中间平台的处理方案,可以更好地将数据作为资产来管理,作为知识来应用~
至此,“Hadoop、Lambda、kappa有什么用”的研究结束,希望能解决大家的疑惑。理论和实践的结合可以帮助你学得更好。去试试吧!如果你想继续学习更多的相关知识,请继续关注网站,边肖会继续努力,给大家带来更多实用的文章!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/139130.html