
本文是给大家分享大数据中朴素贝叶斯方法的样本分析的内容。我觉得边肖很实用,就和大家分享一下作为参考。让我们跟着边肖看一看。
两个最广泛使用的分类模型是决策树模型和朴素贝叶斯模型(NBM)。这种情况下采用朴素贝叶斯模型。朴素贝叶斯方法是基于贝叶斯定理和特征条件独立假设的分类方法。本节重点分析这种算法。
一、 垃圾消息识别算法-朴素贝叶斯
与决策树模型相比,源于经典数学理论的朴素贝叶斯分类器具有坚实的数学基础和稳定的分类效率。同时,NBC模型需要估计的参数较少,对缺失数据不太敏感,算法相对简单。
理论上,与其他分类方法相比,NBC模型的错误率最小。但事实上,情况并非总是如此。这是因为NBC模型假设属性相互独立,在实际应用中往往不成立,这对NBC模型的正确分类有一定的影响。
这个250多年前发明的算法,在信息领域有着无与伦比的地位。贝叶斯分类是一系列分类算法的总称,它们都是基于贝叶斯定理,所以统称为贝叶斯分类。朴素贝叶斯算法是应用最广泛的分类算法之一。
1.实现基础机器学习贝叶斯分类的核心
分类是预先把一个未知样本分成几个已知类别的过程。解决数据分类问题是一个两步走的过程:第一步是建立一个模型来描述数据集或概念的预设。通过分析样本(或实例、对象等)来构建模型。)由属性描述。假设每个样本都有一个预定义的类,这个类由一个名为class label的属性决定。为建模而分析的数据元组形成训练数据集,这也称为引导学习。
在众多分类模型中,应用最广泛的两种分类模型是决策树模型和朴素贝叶斯模型。决策树模型通过构造一棵树来解决分类问题。首先,通过训练数据集构建决策树。一旦树建立起来,它就可以为未知样本生成一个分类。
在分类问题中使用决策树模型有很多优点。决策树易于使用且高效。规则可以很容易地根据决策树构建,规则通常很容易解释和理解。决策树可以很好地扩展到大型数据库,它的大小与数据库的大小无关。决策树模型的另一个巨大优势是它可以为具有许多属性的数据集构建决策树。决策树模型也存在一些缺点,如难以处理缺失数据、过拟合问题、忽略数据集中属性之间的相关性等。
这个问题的一般解决方案是建立一个属性模型,并分别处理彼此不独立的属性。例如,在对中文文本进行分类和识别时,我们可以建立一个字典来处理一些短语。如果发现某个具体问题中有特殊的模式属性,应该分别处理。
这也符合贝叶斯概率原理,因为我们把一个短语看成一个单一的模式,比如英语文本中一些长短不一的单词也被当作独立的模式来对待,这就是自然语言和其他分类识别问题的区别。
当计算实际先验概率时,结果是相同的,因为这些模式是由程序作为概率计算的,而不是人们用自然语言理解的。
当属性数量较大或属性间相关性较大时,朴素贝叶斯模型的分类效率不如决策树模型。但是这一点需要验证,因为具体问题不同,算法得到的结果也不同。对于同一问题,只要模式发生变化,同样的算法也有不同的识别性能。这一点在国外的很多论文中都有所认识。该算法对属性的识别依赖于许多因素,如训练样本与测试样本的比例,这影响了算法的性能。
对于通过决策树进行文本分类和识别,这取决于具体情况。当属性相关性较小时,朴素贝叶斯模型的性能相对较好。当属性相关性较大时,决策树算法具有更好的性能。
2.朴素贝叶斯分类的表达式描述
贝叶斯推理是由英国数学家托马斯贝叶斯在1702-1761年开发的,用来描述两个条件概率之间的关系,如P(A|B)和P(B|A)。根据乘法法则,我们可以立即推导出:P(AB)=P(A)* P(B | A)=P(B)* P(A | B)。上述公式也可以转化为:P(B|A)=P(A|B)*P(B)/P(A)。
一般情况下,事件A在事件B条件下的概率与事件B在事件A条件下的概率不同;但是两者之间是有一定关系的,贝叶斯定律就是这种关系的表述。贝叶斯规则是关于随机事件A和B的条件概率和边际概率,其中P(A|B)是B发生时A发生的概率。
在贝叶斯定律中,每个名词都有一个习惯名称:
Pr(A)是A的先验概率或边际概率,之所以叫“先验”,是因为它没有考虑任何B因素。
Pr(A|B)是已知B发生后A的条件概率,由于从B得到的值,又称为A的后验概率。
Pr(B|A)是A已知后B的条件概率,由于从A得到的值,也称为B的后验概率。
Pr(B)是B的先验概率或边际概率,也叫归一化常数。
根据这些术语,贝叶斯规则可以表示为:
p>后验概率 = (似然度 * 先验概率)/标准化常量,也就是说,后验概率与先验概率和似然度的乘积成正比。
另外,比例Pr(B|A)/Pr(B)也有时被称作标准似然度(standardised likelihood),Bayes法则可表述为:
后验概率 = 标准似然度 * 先验概率。
二、 进行分布式贝叶斯分类学习时的全局计数器
在单机环境中完成基于简单贝叶斯分类算法的机器学习案例时,只需要完整加载学习数据后套用贝叶斯表达式针对每个单词计算统计比率信息即可,因为所需的各种参数均可以在同一个数据文件集中直接汇总统计获取,但是当该业务迁移到MapReduce分布式环境中后,情况发生了本质的变化。从图14.9贝叶斯分类表达式在垃圾消息识别中的使用方式:


可以看出,在进行数据学习统计时需要计算几个主要比例参数:可以看出,在进行数据学习统计时需要计算几个主要比例参数:
-
所有消息中包含某个特定单词的比率;
-
消息为垃圾消息的比率;
-
消息为垃圾消息并且垃圾消息中存在特定单词的比例。
因此,需要对所有的学习数据汇总,至少需要明确学习数据中消息的总数,学习数据中垃圾消息的数量,学习数据中有效消息的数量等数据,由于MapReduce任务的数据输入来源来自于HDFS,而HDFS会将超大的数据文件自动切分成大小相等的块存放到不同的数据节点,同时MapRedece任务也将满足“数据在哪个节点,计算任务就在哪个节点启动”的基本原则,因此整个学习数据的分析统计任务会并行在不同的Java虚拟机甚至不同的任务计算节点中,使用传统的共享变量方式来解决这个汇总统计问题就成了不可能完成的任务。
要想使用MapReduce完成计数器的功能可以有以下几种选择:
(1)使用MapReduce内置的Counter组件,MapReduce的Counter计数器会自动记录一些通用的统计信息,如本次MapReduce总共处理的数据分片数量等,开发人员也可以自定义不同类型的Counter计数器并在Map或Reduce任务中设置/累加/计数器的值,但是MapReduce内置的Counter计数器工具有一个明显的缺陷,它并不支持Map任务中累加计数器的值后在Reduce中直接获取。
也就是说,在Reduce任务中第一次获取相关计数器的值永远都为0,尽管在整个任务结束后,MapReduce会将对应计数器在Map和Reduce两个任务过程中分别设置的值进行最终的累加操作,由于在本案例中需要在Reduce任务中获取有效/垃圾消息的总数量以计算比率信息,而这些数量需要在Map任务中统计,因此MapReduce内置的Counter计数器并不是适合本案例的应用环境。
(2)Hadoop生态中的特殊组件Zookeeper对这类跨越节点的统一计数器提供了API支持,但是如果仅仅是因为需要设置少量几个以数字形式存在的计数器就额外部署一套Zookeeper集群显然开销太大,因此这种解决方法也不适用于当前案例。
(3)自行实现简单的统一计数器。统一计数器的实现比较简单,仅需在单独的节点中定义数字变量,在需要设置、累加或获取计数器时通过都通过网络访问这个节点中的这些数字变量。在普通环境中,实现这样一个计数器服务相对较为繁琐,因为需要大量的网络数据交换操作,但是在实现了自定义的RPC调用组件之后,基于网络的数据设置和获取操作就显得异常简单,就类似于在本机上完成一次普通Java方法一样方便,因此可以按照以下的结构来完成计数器服务的实现:
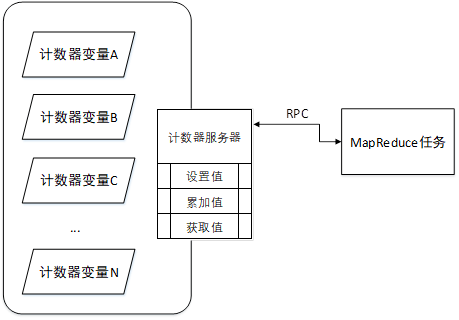
注意:由于多个数据处理节点会并发的向计数器服务发起设值请求,因此需要注意计数器变量的安全性,在最为简单的设计中,使计数器服务的设置值、累加值、获取值方法保持同步即可。
三、数据清洗分析结果存储
MapReduce是典型的非实时数据处理引擎,这就意味着不能将其作为需要实时反馈的场景。所以MapReduce任务只能在后台完成复杂数据的处理操作,供终端实时运算提供支撑的中间结果,而且由于HDFS文件系统的Metadata检索服务和数据网络传输都需要大量的IO开销,如果中间结果集的量级并不需要分布式的文件存储支持而又使用HDFS存储中间结果,反倒会对最终的服务效率带来消极影响。因此在完成好数据的统一清洗分析后,中间结果一般都选择以下的几种保存策略:
-
如果清洗后的结果是量级较小的规则性数据,则可以将其直接存放到Redis之类的Key-Value高速缓存体系中;
-
如果清洗后的结果集比较大,那么可以在Reduce任务中将其存放到传统的RDBMS中,供业务系统使用SQL语句完成实时查询;
-
如果清洗后的结果仍然是海量数据,则可以将其存放到HBase之类的分布式数据库中以提供高效的大数据实施查询。
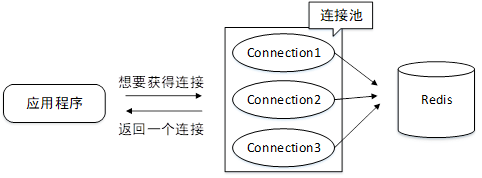
本项目采用Redis缓存数据,并使用了Redis连接池。和RDBMS一样,Redis也可以通过连接池方式提高数据访问效率和吞吐量,其原理如下:
感谢各位的阅读!关于“大数据中朴素贝叶斯法的示例分析”这篇文章就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/145156.html