
本文将详细阐述基于Spark Mllib的文本分类的实例分析。边肖觉得挺实用的,分享给大家参考。希望你看完这篇文章能有所收获。
基于Spark Mllib的文本分类
文本分类是一个典型的机器学习问题,其主要目标是通过训练已有的语料库文本数据得到分类模型,进而预测新文本的类别标签。在很多领域都有实际的应用场景,比如新闻网站的新闻自动分类、垃圾邮件检测、非法信息过滤等等。本文将对一个手机短信样本数据集进行训练,对新的数据样本进行分类,进而检测其是否为垃圾短信。基本步骤是:首先将文本句子转换成单词数组,然后使用Word2Vec工具将单词数组转换成k维向量。最后通过训练k维向量样本数据得到前馈神经网络模型,从而实现文本的类别标签预测。本文利用单词矢量量化工具Word2Vec和Spark ML中的多层感知器分类器来实现这种情况。
Word2Vec简介
Word2Vec是一个用来将单词表示为数字向量的工具。它的基本思想是将文本中的单词映射成K维数值向量(通常用K作为算法的超参数),使文本中的所有单词形成一个K维向量空间,这样我们就可以通过计算向量之间的欧氏距离或余弦相似度得到文本的语义相似度。Word2Vec采用分布式表示的词向量表示,既能有效控制词向量的维数,避免维数灾难(相对于一热表示),又能保证相似意义的词在向量空间中更接近。
Word2Vec的实现有两种模式:CBOW(连续词包)和Skip-Gram。简单总结一下,区别在于CBOW根据上下文预测目标词,Skip-Gram根据当前词预测上下文。Spark是通过Skip-Gram模型实现的。假设我们有n个待训练的单词序列样本,表示为W1,W2.Wn,而Skip-Gram模型的训练目标是最大化平均对数似然,即
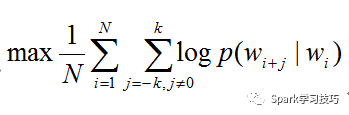

其中n是单词的数量,k是单词上下文的窗口大小。在Skip-Gram模型中,在某个上下文窗口中每两个单词之间计算概率,通常上下文窗口越大,可以覆盖的单词组合越全面,可以带来更准确的结果,但缺点是也会增加训练时间。
在Skip-Gram模型中,每个单词与两个向量相关联,这两个向量分别表示单词向量和上下文向量。也正是因为如此,Word2Vec才能比传统的LDA(潜在狄利克雷分配)过程表达更丰富、更准确的语义信息。
Spark的Word2Vec实现提供了以下主要可调参数:
Col,存储在源数据数据框中的文本单词数组列的名称。
输出,已处理的数字特征向量存储列的名称。
默认情况下,目标数值向量的尺寸大小为100。
窗口大小,上下文窗口的大小,默认为5。
NumPartitions,训练数据的分区数,默认为1。
MaxIter,算法找到最大迭代次数,小于或等于分区数。默认值为1。
minCount,只有当一个单词的出现次数大于等于MinCount时,才会被包含在词汇中,否则会被忽略。
步长,优化算法每次迭代的学习速率。默认值为0.025。
这些参数可以在构造Word2Vec实例时通过setXXX方法进行设置。
多层感知器
多层感知器(MLP)是一种多层前馈神经网络模型。所谓前馈神经网络是指它只从输入层接收前一层的输入,并将计算结果输出到下一层,而不对前一层给出反馈。整个过程可以用一个有向无环图来表示。这种类型的神经网络由三层组成,即输入层、一个或多个隐藏层和输出层,如图所示:

Spark ML在1.5版之后提供了一个由BP(反向传播)算法训练的多层感知器实现。BP算法的学习目的是研究网络。
的连接权值进行调整,使得调整后的网络对任一输入都能得到所期望的输出。BP 算法名称里的反向传播指的是该算法在训练网络的过程中逐层反向传递误差,逐一修改神经元间的连接权值,以使网络对输入信息经过计算后所得到的输出能达到期望的误差。Spark 的多层感知器隐层神经元使用 sigmoid 函数作为激活函数,输出层使用的是 softmax 函数。
Spark 的多层感知器分类器 (MultilayerPerceptronClassifer) 支持以下可调参数:
-
featuresCol:输入数据 DataFrame 中指标特征列的名称。
-
labelCol:输入数据 DataFrame 中标签列的名称。
-
layers:这个参数是一个整型数组类型,第一个元素需要和特征向量的维度相等,最后一个元素需要训练数据的标签取值个数相等,如 2 分类问题就写 2。中间的元素有多少个就代表神经网络有多少个隐层,元素的取值代表了该层的神经元的个数。例如val layers = Array[Int](100,6,5,2)。
-
maxIter:优化算法求解的最大迭代次数。默认值是 100。
-
predictionCol:预测结果的列名称。
-
tol:优化算法迭代求解过程的收敛阀值。默认值是 1e-4。不能为负数。
-
blockSize:该参数被前馈网络训练器用来将训练样本数据的每个分区都按照 blockSize 大小分成不同组,并且每个组内的每个样本都会被叠加成一个向量,以便于在各种优化算法间传递。该参数的推荐值是 10-1000,默认值是 128。
算法的返回是一个 MultilayerPerceptronClassificationModel 类实例。
目标数据集预览
在引言部分,笔者已经简要介绍过了本文的主要任务,即通过训练一个多层感知器分类模型来预测新的短信是否为垃圾短信。在这里我们使用的目标数据集是来自 UCI 的 SMS Spam Collection 数据集,该数据集结构非常简单,只有两列,第一列是短信的标签 ,第二列是短信内容,两列之间用制表符 (tab) 分隔。虽然 UCI 的数据集是可以拿来免费使用的,但在这里笔者依然严正声明该数据集的版权属于 UCI 及其原始贡献者。

数据集下载链接:http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
案例分析与实现
在处理文本短信息分类预测问题的过程中,笔者首先是将原始文本数据按照 8:2 的比例分成训练和测试数据集。整个过程分为下面几个步骤
-
从本地读取原始数据集,并创建一个 DataFrame。
-
使用 StringIndexer 将原始的文本标签 (“Ham”或者“Spam”) 转化成数值型的表型,以便 Spark ML 处理。
-
使用 Word2Vec 将短信文本转化成数值型词向量。
-
使用 MultilayerPerceptronClassifier 训练一个多层感知器模型。
-
使用 LabelConverter 将预测结果的数值标签转化成原始的文本标签。
-
最后在测试数据集上测试模型的预测精确度。
算法的具体实现如下:
1, 首先导入包
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, Word2Vec}
2, 创建 集并分词
val parsedRDD = sc.textFile("file:///opt/datas/SMSSpamCollection").map(_.split(" ")).map(eachRow => {
(eachRow(0),eachRow(1).split(" "))
})
val msgDF = spark.createDataFrame(parsedRDD).toDF("label","message")
3, 将标签转化为索引值
val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(msgDF)
4, 创建Word2Vec,分词向量大小100
final val VECTOR_SIZE = 100
val word2Vec = new Word2Vec().setInputCol("message").setOutputCol("features").setVectorSize(VECTOR_SIZE).setMinCount(1)
5, 创建多层感知器
输入层VECTOR_SIZE个,中间层两层分别是6,,5个神经元,输出层2个
val layers = Array[Int](VECTOR_SIZE,6,5,2)
val mlpc = new MultilayerPerceptronClassifier().setLayers(layers).setBlockSize(512).setSeed(1234L).setMaxIter(128).setFeaturesCol("features").setLabelCol("indexedLabel").setPredictionCol("prediction")
6, 将索引转换为原有标签
val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labels)
7, 数据集分割
val Array(trainingData, testData) = msgDF.randomSplit(Array(0.8, 0.2))
8, 创建pipeline并训练数据
val pipeline = new Pipeline().setStages(Array(labelIndexer,word2Vec,mlpc,labelConverter))
val model = pipeline.fit(trainingData)
val predictionResultDF = model.transform(testData)
//below 2 lines are for debug use
predictionResultDF.printSchema
predictionResultDF.select("message","label","predictedLabel").show(30)
9, 评估训练结果
val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("precision")
val predictionAccuracy = evaluator.evaluate(predictionResultDF)
println("Testing Accuracy is %2.4f".format(predictionAccuracy * 100) + "%")

关于“基于Spark Mllib文本分类的示例分析”这篇文章就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/148261.html