
今天和大家聊聊TransOMCS中从语言图中提取常识知识的实例分析,可能很多人都不太懂。为了让大家更好的了解,边肖为大家总结了以下内容,希望大家能从这篇文章中有所收获。
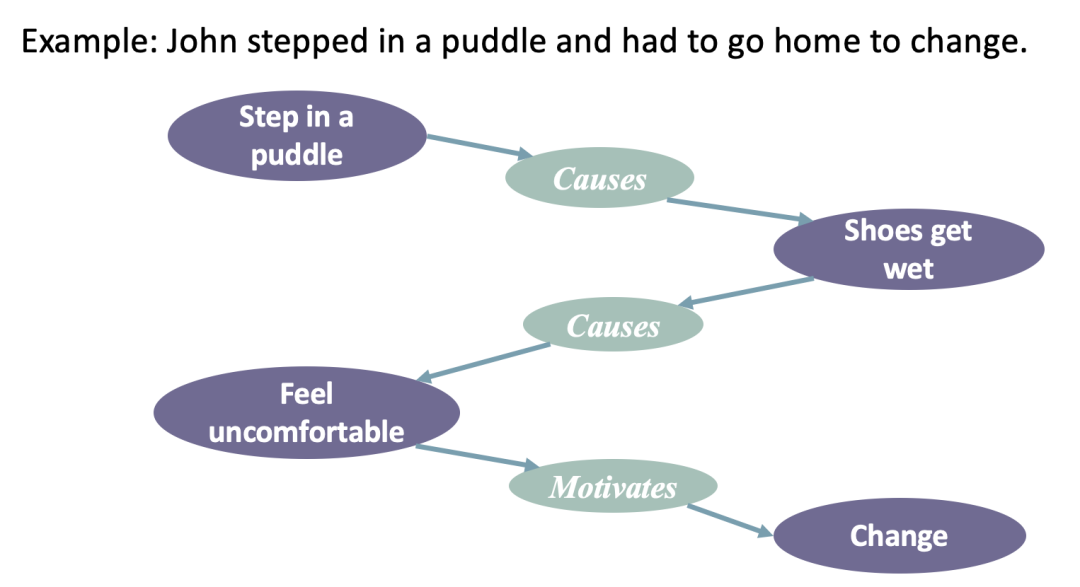
一、背景:毫无疑问,常识在NLU极其重要。下图就是一个例子。人类很容易理解“踩进水坑”和“回家换鞋”这两个事件是怎么联系在一起的,因为我们知道踩进水坑会导致鞋子湿,湿了的鞋子会让人感觉不舒服,所以自然会想回家换鞋。由此可见,常识与事件息息相关。
什么是常识?一个流行的定义是“对于正常人来说,常识一般是指对周围事件的良好判断”。在AI领域,常识通常被用作指代“大多数人公认的百万级的基本事实和理解”.的术语常识和事实的一个重要区别是,隐性常识是众所周知的,在社会交往中,为了高效的沟通,往往会被忽视。比如“如果你忘记了一个人的生日,他可能会很生气”“鸟会飞,书不会飞”,这些在日常交流中不需要重复。另一个重要的区别是,与事实不同,常识更多的是一种倾向,并不总是正确的。就像上面两个例子,如果你的朋友知道你最近很忙,即使你忘记了他的生日,他可能也不会生气。不是所有的鸟都能飞,像鸵鸟一样。

为了帮助机器常识,有很多常识资源,常识知识库是人工智能建立的。比较有名的是概念网/OMCS(开放思维常识)。最初的OMCS包含20种常识关系,最新的ConceptNet 5.0在OMCS的基础上扩展到33种。除了常识,还涉及到WordNet的相关知识。
最近,一个叫做ATOMIC的常识数据集包含了大量生活事件的常识,并使用了人们定义的九种关系。然而,这些人工构建常识知识库的方法总是存在一些局限性:(1)只能覆盖选定的边;(2)寻找新的边缘需要大量的金钱和时间。


要突破以上局限,自然的思路是能否从自然语言中自动获取常识。要研究这个问题,首先需要弄清常识在自然语言中是如何表达的,这要追溯到语义理论的下界。语言描述没有语法却有语义。理解语言既需要“说话者的语言知识”,也需要“关于世界的知识”,其中“世界知识”包括事实和常识。
在下面的例子中,三个句子具有相同的语法,但是描述了三个完全不同的事件。但是在说“太危险”的时候,“它”这个句子显然更喜欢三个选项中的“狮子”,因为这是常识。总而言之,当语法被困定时,我们做出的选择可以反映出我们对世界的理解。

从语言学上来说,这被称为选择偏好,是选择限制,的概括,经常被用作一个非常重要的语言特征。起初,它只适用于WordNet中的IsA层次结构和谓词-对象关系。通过这个公式,我们可以很容易地使用频率/合理性分数的不同组合来反映人们的偏好。例如,模型或知识库可以给出三元组(“猫”-ISA-“anima”
l”) 的分数高于(“Cat”-IsA-“Plant”),就可以认为这个模型或知识库具备了“猫是一种动物,而不是植物”的常识。

只有以上两种关系是不能覆盖全部常识知识的,因此学术界也尝试进行了探索,如下图所展示的。一阶关系,比如扩展到主语位。二阶关系,有时对于一个事件来说,我们对它的主语和谓语没有直接要求和倾向性,但对于主语和谓语的特征有很直接的倾向性。进一步拓展,可以得到更高阶的关系,事件之间的倾向性。如下图所示这项工作,主要研究了语言关系的选择偏好与人类定义的常识之间的联系。

二、TransOMCS模型框架
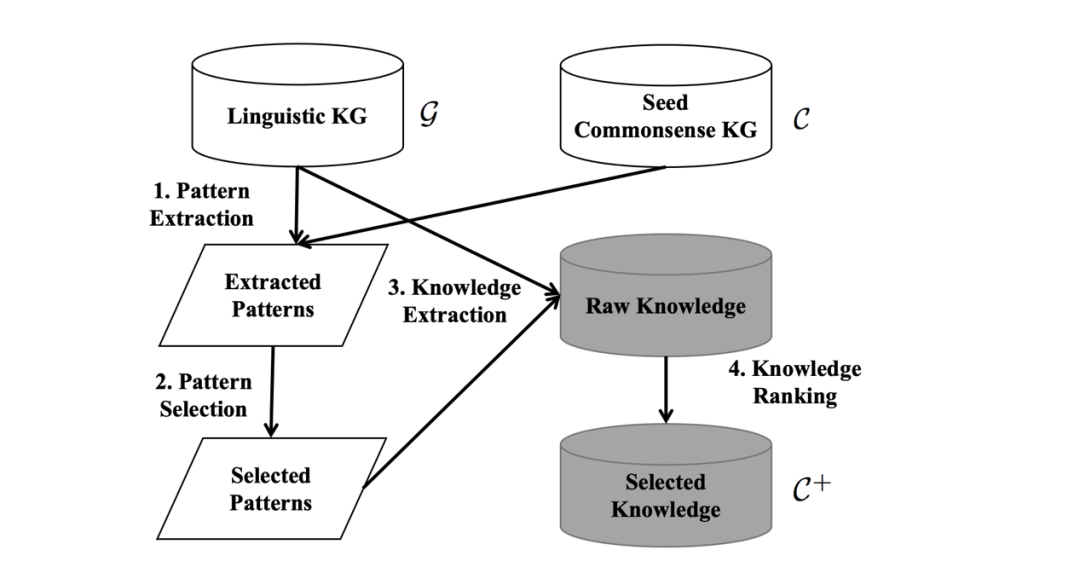
上面已经提到获取常识的常规方法通常需要费力且昂贵的人工注释,这在大规模上是不可行的。对此,张洪铭等探索出了一种新的实用方法——TransOMCS,从语言图中提取常识知识,目的是将通过语言模式获得的廉价知识转化为昂贵的常识知识。下图为这项工作的总体框架。
⑴首先对语言知识图和种子常识知识图两个数据集进行模式提取,但提取得到的模式可能存在噪音,因此在此基础上需要进一步的清洗和挑选。
⑵然后,在获取到高质量的模式后,可以迁移回原始的语言知识图,从而得到大量的常识知识。
⑶最后,对获取到的常识知识进行打分,得到最终更高质量的常识。整个过程不需要额外的标注,因此十分便宜且具有较好的拓展性。
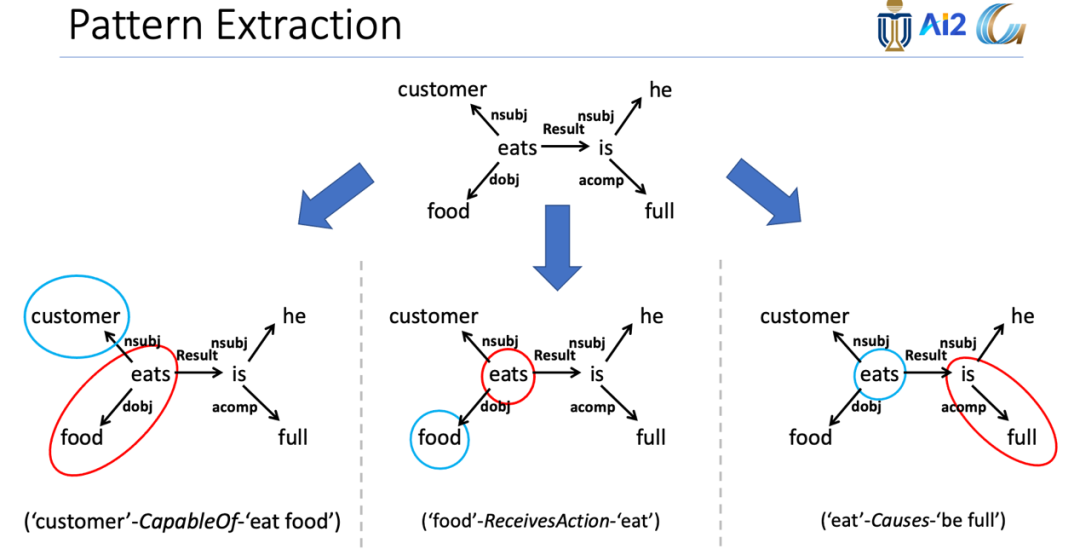
下图为针对不同常识关系语言图和提取模式的示例,这些模式是通过种子常识元组和图中的单词匹配来提取的。给定语言图作为输入,可以将这些模式应用于提取类似OMCS的常识。提取的头部和尾部概念分别用蓝色和红色圆圈表示。
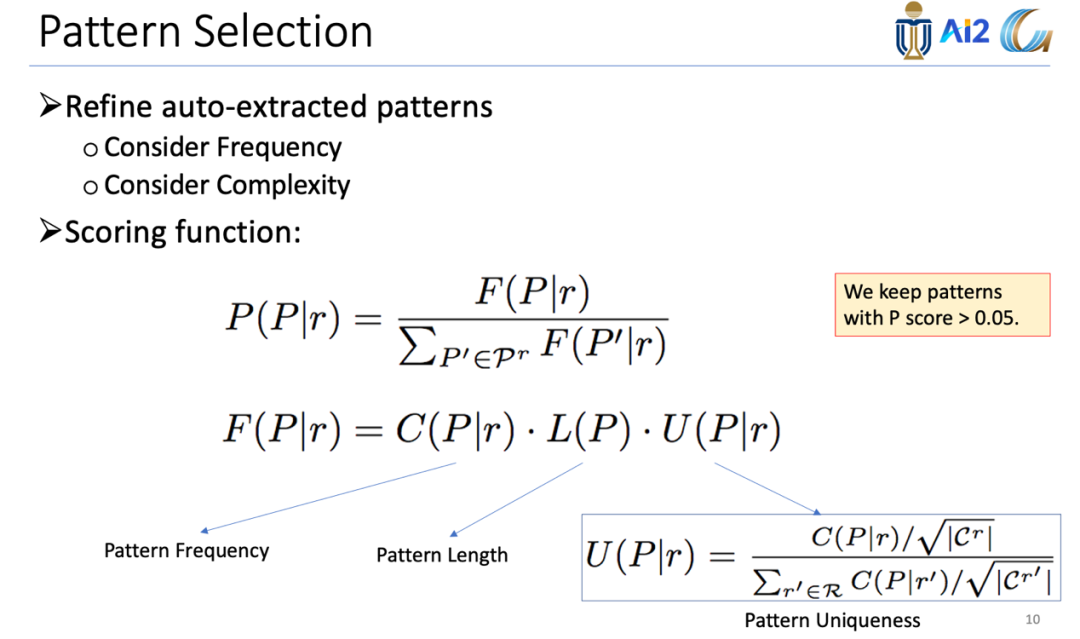
模式选择需要重新精炼自动提取的模式,在这个过程中,应综合考虑高频率和复杂性两个因素。对于每个模式,并不是简单看其本身的分数,而是需要将所有的候选模式经过对比分析,选择置信度更高的。
为了最大程度地减小模型噪声的影响,提出了一个知识排名模块,根据置信度对所有提取的知识进行排名。这里的置信度主要利用原始句子的语义和频率两方面的信息。
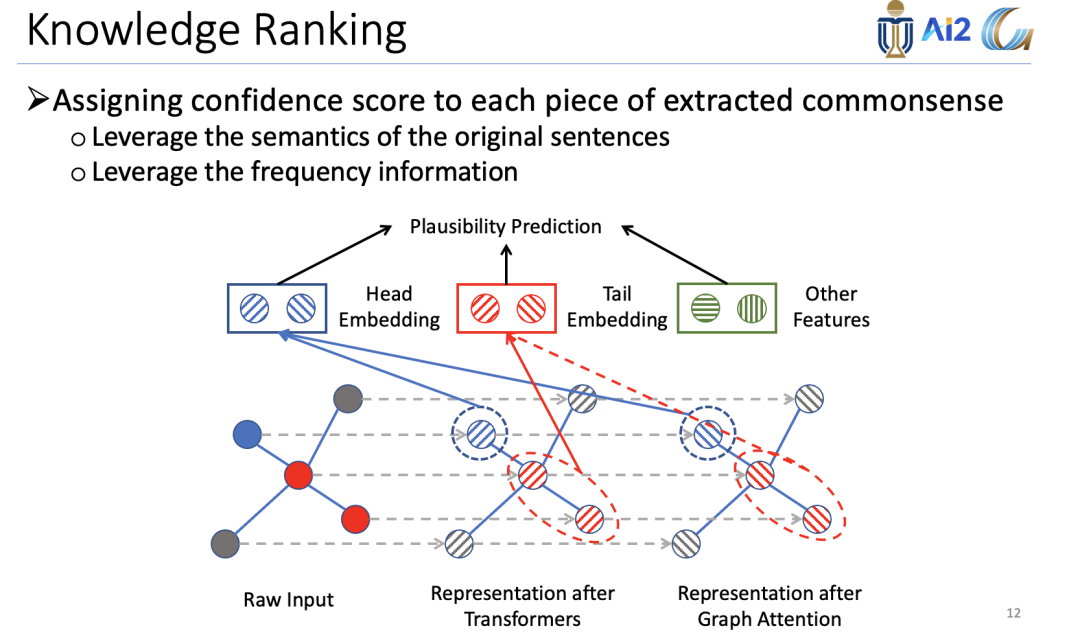
三、实验结果
实验部分,将ASER作为语言知识图,种子常识知识图则采用OMCS/ConceptNet。结果是输入了一个大型的常识库——TransOMCS,是由OMCS格式转换而来的。虽然TransOMCS与OMCS类似,但其规模约是OMCS的一百多倍。另外,在与人工标注的对比中发现,TransOMCS是拥有高质量的高置信度。最重要的是,这几乎没有任何成本。
下表列出了模型评估的摘要,主要对比了COMET和LAMA两个基准模型。从表中可以看出,TransOMCS在数量上胜于另外三个模型,即使是TransOMCS的最小子集也要比其他最大生成策略高出10倍。另外,TransOMCS在新颖性方面也优于COMET,尤其是新颖概念的百分比。其背后的原因在于COMET是一种纯粹的机器学习方法,它在训练集上学习生成尾部概念。模型越强大,就越可能拟合训练数据,产生的新颖概念就越少。因此,通过实验证明了确实可以将语言知识转移为常识知识,SP可以有效地表示常识。

下图为案例研究,以进一步分析不同的获取方法。COMET是唯一可以生成长概念的模型,但同时它也遭受生成无意义单词的困扰。除此之外,COMET可能会拟合训练数据,即使十个输出不完全相同,但其中四个都表示同一件事。
LAMA的最大优势在于它不受监督,但它有两个主要缺点:(1)它只能生成one-token的概念,对于常识知识来说还远远不够;(2)LAMA的质量不如其他两种方法。
与COMET相比,TransOMCS可以产生更多新颖的常识知识。同时,与LAMA不同,TransOMCS可以生成multi-token概念。但TransOMCS也有两个局限性:(1)无法提取长概念,很难找到精确的模式匹配;(2)由于提取过程严格遵循模式匹配,因此可能提取语义不完整的知识。

实验的最后,还设计了常识阅读理解和日常对话生成两个下游任务,结果显示如下图。对于阅读理解任务,TransOMCS有助于提高总体的准确性,而COMET和LAMA对于此任务的贡献很小。对于日常对话生成任务,TransOMCS在生成的响应质量上表现出显著的提高。
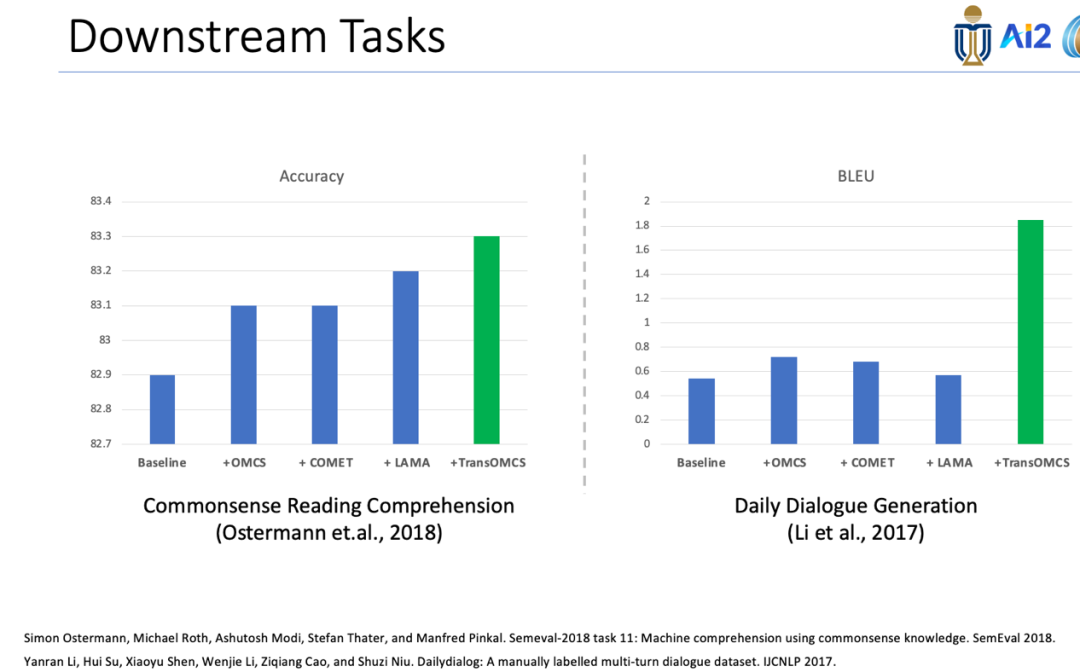
简单总结来说,讲者这项工作证明了从语言知识到常识的可转移性,提出了可自动获取常识的可扩展的模型。另外,还设计了TransOMCS,它比OMCS大两个数量级。
四、DISCOS: 从ASER到ATOMIC
除了TransOMCS这项工作,张洪铭博士还介绍了他参与的另一项工作DISCOS,目前已被WWW 2021所接收。同样针对先前常识获取方法的局限性,DISCOS常识获取框架也希望自动从更实惠的语言知识资源中挖掘昂贵的复杂常识知识。
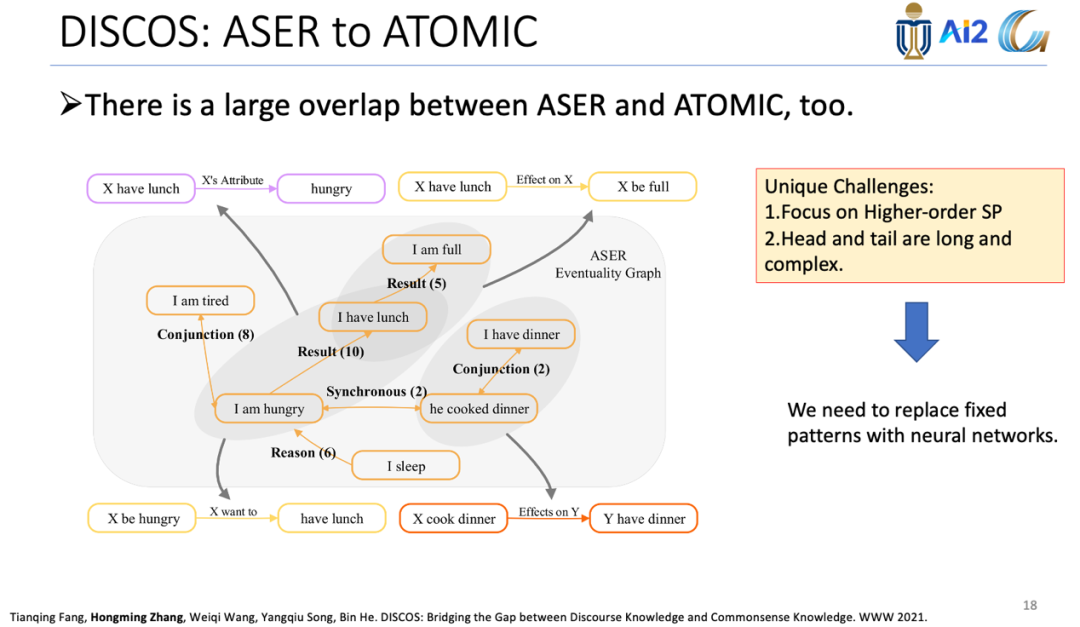
下图是DISCOS的一个示例,来自ASER的最终事件通过指示相应话语关系的有向边连接起来。DISCOS旨在将ASER中的话语边转换为“如果-那么”的常识边。例如,ASER边(“我饿了”,结果是“我吃了午餐”)将被转换为(如果“ X饿了”,那么X想要“吃午饭”)常识元组。与OMCS不同,DISCOS只专注于更高阶的SP,它的头和尾通常是长且复杂的,因此需要用神经网络代替固定模式。
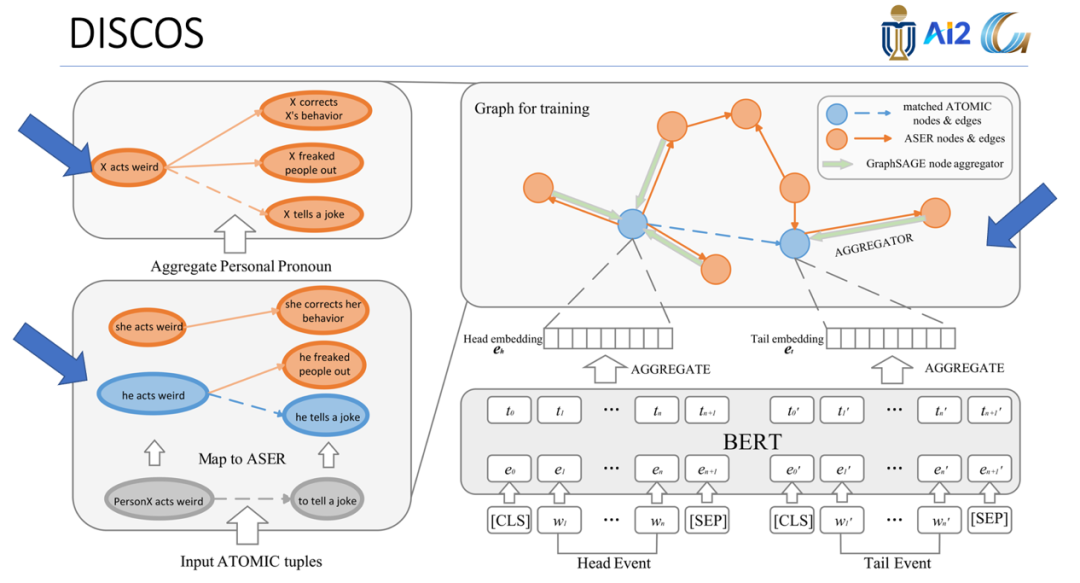
DISCOS的总体框架如下图,ATOMIC和ASER中的事件主体完全不同,在ATOMIC中主体是诸如“Person X”和“ Person Y”的占位符,而在ASER中则是具体人称代词“他”和“她”。为了对齐两个资源,首先将ATOMIC中的所有头和尾映射到ASER中。形式上,需要一个映射函数将输入的字符串映射到ASER中相同的节点格式。接下来,在给定节点和常识关系的情况下,利用规则选择候选话语边。最后,采用一种新颖的常识知识种群模型BERTSAGE来对候选常识元组的合理性进行评分。
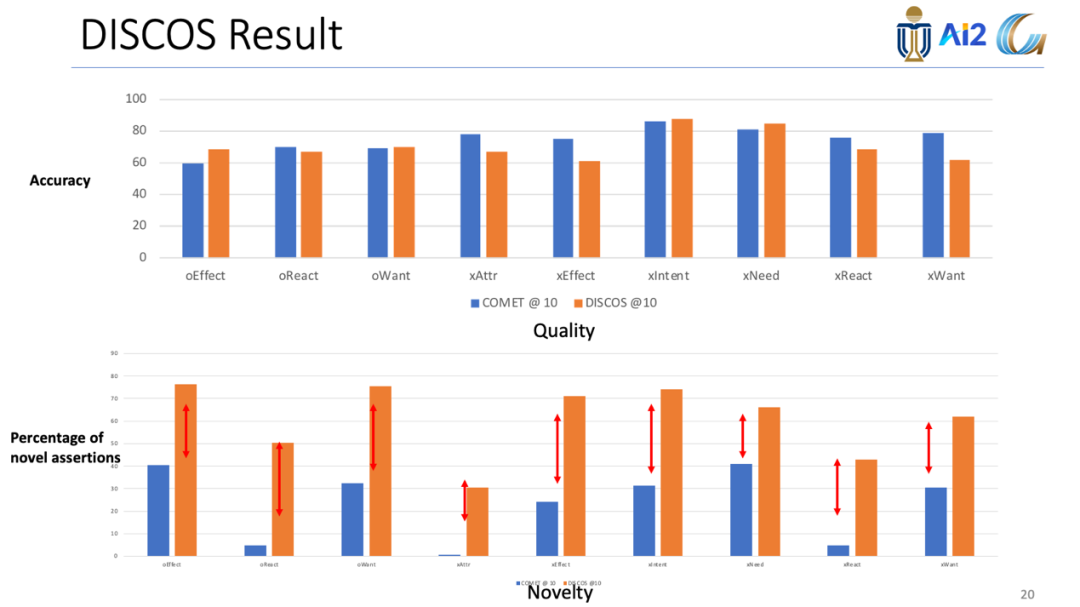
如下表的实验结果显示,虽然COMET和DISCOS在质量上相差不大,但是在新颖性方面DISCOS大大胜于COMET。
总结来说,TransOMCS和DISCOS都证明了从语言知识到简单常识和复杂常识的可转移性,这就意味着过去费力且昂贵的方法是可以被取代的,TransOMCS、DISCOS等自动获取的方式不仅便宜且可扩展性更优。
看完上述内容,你们对TransOMCS中从语言图提取常识知识的示例分析有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注行业资讯频道,感谢大家的支持。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/148964.html