
本文介绍了一个Spark有向无环图检测的实例分析,非常详细。感兴趣的朋友可以参考一下,希望对你有所帮助。
01
—
火花背景介绍
Apache Spark是为大规模数据处理而设计的快速通用计算引擎。Spark是一个类似于Hadoop的开源集群计算环境,具有Hadoop MapReduce的优势。但是,与MapReduce不同,——Job的中间输出可以存储在内存中,因此不再需要读写HDFS。因此,Spark更适合数据挖掘、机器学习等需要迭代的MapReduce算法。
RDD称为弹性分布式数据集,是一种容错和并行的数据结构,它允许用户明确地将数据存储在磁盘和内存中,并控制数据分区。RDD是Spark的灵魂,一个RDD代表一个可以分区的只读数据集。RDD可以有很多分区,每个分区都有大量的记录。
RDD之间的依赖关系用有向无环图表示。让我们来看看有向无环图的基本理论和算法。
02
—
有向无环图
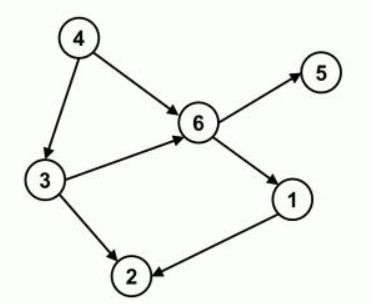
在图论中,有无向边的图叫做无向图,有无向边的图叫做有向图。在无向图的基础上,如果任何一个顶点不能通过几条边回到这个点,那么这个图就没有循环,这就是有向无环图(DAG图)。如下图所示,4-6-1-2是一条路径,4-6-5也是一条路径,图中没有一个顶点可以通过几条边回到这个点,所以可以得出下图是DAG。

学位内
渗透度是图论算法中的重要概念之一。通常指有向图中某一点是图中边的终点的次数之和,即项目点的进入边数称为项目点的进入度。如上图所示,顶点4的穿透程度为0。
不学位
对应于入度,顶点的边数称为顶点的出度。如上图所示,顶点3的穿透程度为2。
03
—
DAG应用程序的另一个例子
在一些任务安排和调度问题上。不同的问题或任务之间有一些依赖关系,有些任务需要先完成才能完成。就像一些学校的教学课程一样。开设某一门课程要看先修课,学生学完先修课才能上这门课。如果将一个课程视为一个节点,则会从该节点引出一个指针,指向其顺序取决于该节点的课程。可能有这样一个图表:
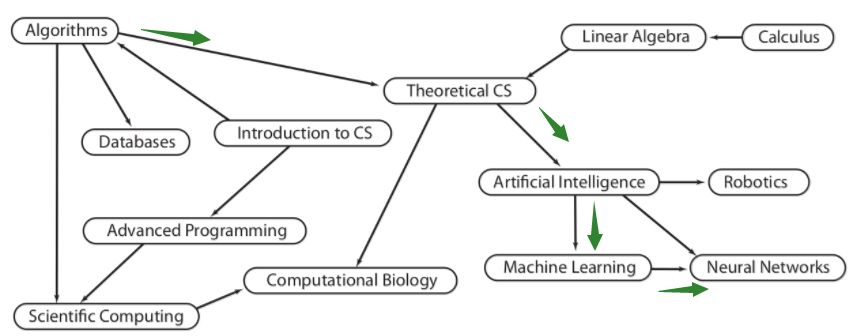
算法课程指向理论CS,意味着后者的选修课需要先完成算法课程,人工智能依赖于理论CS,机器学习依赖于人工智能,神经网络依赖于机器学习课程,称为一条路径。
还可以看到上图中0度的节点有CS的Introduction,这在有向图的遍历中意义重大,下面会提到。
04
—
如果上图有戒指,对吗?
444316.png" alt="Spark有向无环图检测的示例分析">
如上所示,如果Machine learning再指向Theoretical CS,意思是选修Theoretical CS的同学需要先修Machine learning,这个就和原来的路径Artificial Intelligence依赖Theoretical CS,Machine learning 依赖Artificial Intelligence,违背!,并且也不合常理,Theoretical CS是一门基础性的理论课,怎么可能选修它之前要先修完machine learning呢?所以不能有环路,这个图是不正确的。所以,这个图必须为有向无环图!
05
—
有向图如何检测有、无环?
那么,如何检测一个有向图是否是DAG呢?
有向图的环检测,首先对照着无向图的环检测来理解,在无向图中,我们要检测一个图中间是否存在环,需要通过深度优先或广度优先的方式,对访问过的元素做标记。如果再次碰到前面访问过的元素,则说明可能存在环。只做标记,在有向图中检测环路的办法可行吗?
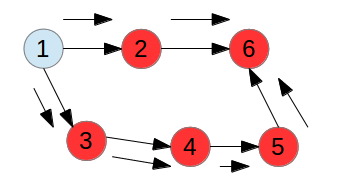
如下图所示,深度优先遍历方法,已经遍历了节点2和6,并marked了,现在遍历节点1的另一条边,依次遍历3,4,5,6,因为6已经遍历,所以说形成了环路,但是实际上并没有,因此,与实际不符合,只对访问过的元素做标记判断有无环路是错误的。
感觉是要加条件,加什么条件? 如果我们加一个数组保存当前节点是否位于递归栈onStack中,就可以排除上面的问题,因为2,6被标记后,依次递归出栈,然后到1,深度遍历1的另一条边(3->4->5->6),所以6此时不在onStack上,第一次被检测到,所以没有环路。
因此,有向图的无环检测,需要同时借助两个限制条件:
-
对访问过的元素做标记
-
当前节点是否位于递归栈onStack中
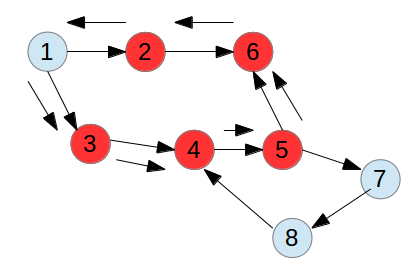
在上图的基础上,增加节点7和8,如下图所示,可以预见,按照深度优先搜索到节点4时,会找到子节点5,节点5的其中一个边找到7,找到8,找到4,节点4此时已经位于onStack中,所以构成环路,是有环图。
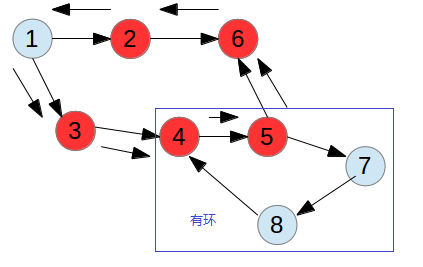
关于Spark有向无环图检测的示例分析就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/149260.html