
相信很多没有经验的人对Pheatmap如何绘制热图都是一窍不通的。为此,本文总结了问题产生的原因及解决方法。希望你能通过这篇文章解决这个问题。
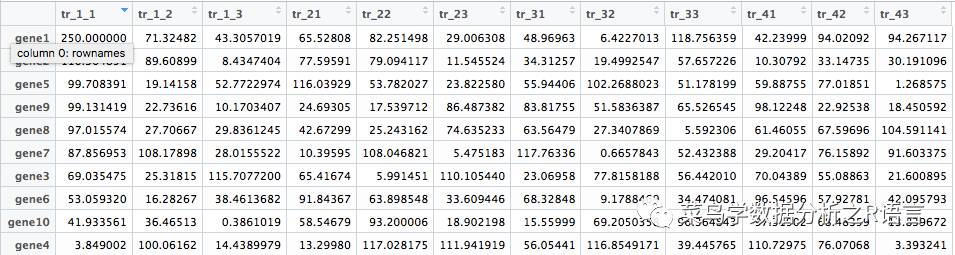
随机产生,10个基因,每个基因4个处理,每个处理3个平行处理,表达RPKM值在1-120之间,矩阵的第一个RPKM值为250:
图书馆
数据矩阵(runif(120,0,120),ncol=12)
数据[1] - 250
colnames(data) - c(paste0('tr_1_ ',seq(1,3))、paste0('tr_2 ',seq(1,3))、paste0('tr_3 ',seq(1,3))、paste0('tr_4 ',seq(1,3)))
row name(data)-c(paste 0(' gene ',seq(1,10)))
运行生成矩阵和图片的过程:

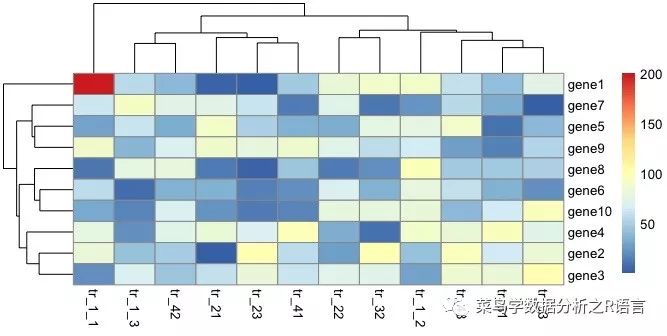
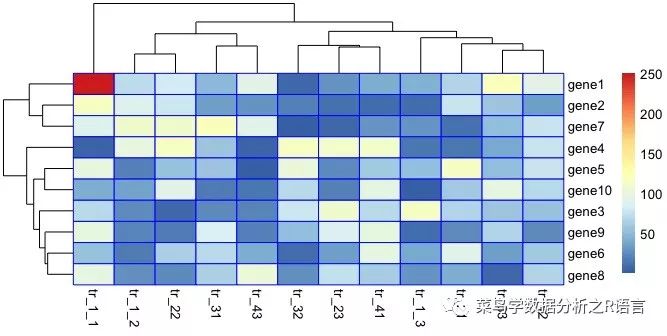
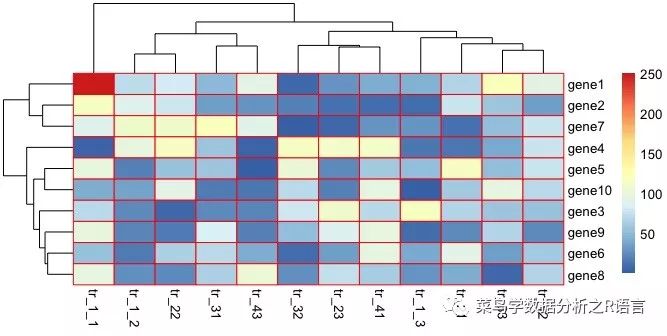
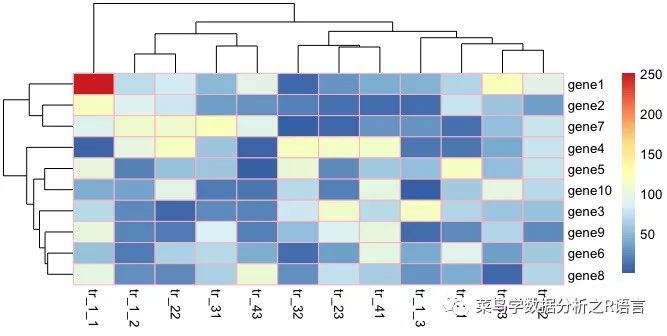
使用边框颜色参数修改边框颜色:
pheatmap(数据,border_color='蓝色')
pheatmap(数据,border_color='red ')
pheatmap(数据,border_color='pink ')
pheatmap(数据,border_color='绿色')
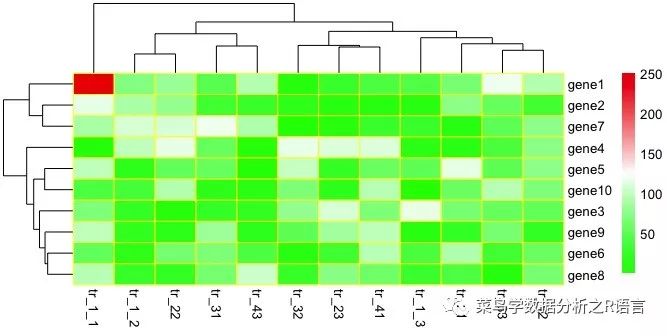
颜色参数的使用:
colors-colorrappalete(c(' blue ',' red')) (5) #颜色从蓝色变为红色,5表示长度为5的颜色渐变。
颜色;色彩;色调
[1]' # 0000 ff ' ' # 3f 00 BF ' ' # 7f 007 f ' ' # BF 003 f ' ' # ff 0000 '
pheatmap(数据,border_color='黄色',color=colorrampalette(c(' 00ff 00 ','白色',' #EE0000'))(100))
操作结果如下:
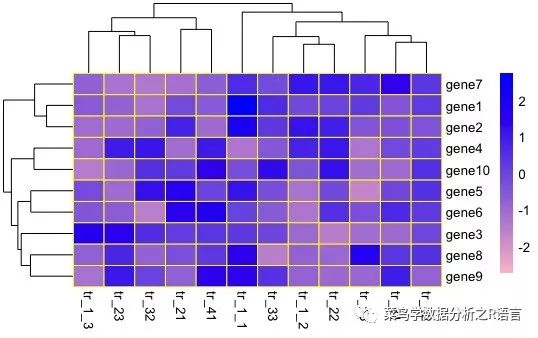
比例参数的使用:
标度是指数值的均匀化。在基因表达的数据中,有的基因极低,有的基因极高。因此,通过将每个基因在不同处理和重复中的数据转换成平均值为0、方差为1的数据,我们可以看出每个基因在某些处理和重复中的表达是高还是低。

“行”、“列”和“无”分别表示均匀化行或列,或者不均匀化它们。在一般的数据处理中,基因的表达应该是同质的,所以选择“行”
pheatmap(数据,border_color=quot
;yellow",color = colorRampPalette(c('pink','blue'))(100),scale='row')
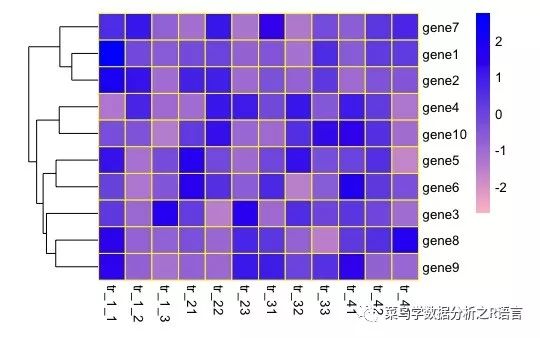
参数:cluster_rows/cluster_cols和cellwidth/cellheight
对基因的顺序进行聚类,因此可使用cluster_rows/cluster_col来修改;同时可以使用cellwidth/cellheight对每个单元方块的大小进行设置:
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20)
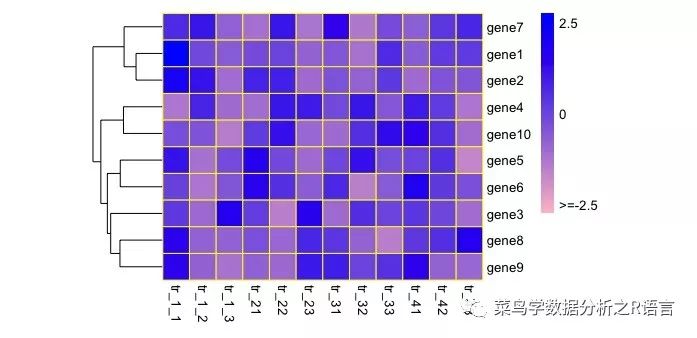
参数:legend/legend_breaks/legend_labels
使用legend阈值逻辑值来对色度条进行隐藏,以及对色度条上对应位置的字符进行修改:
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'))
运行结果如下:
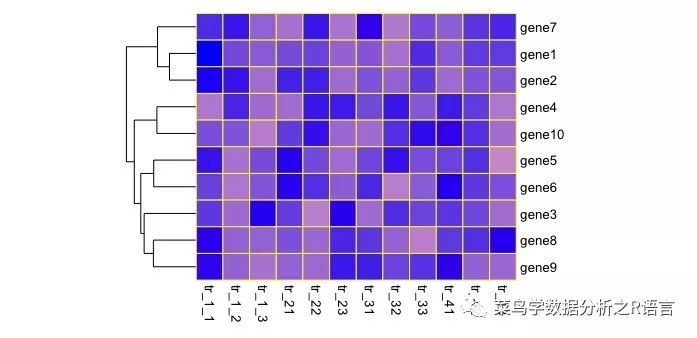
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend=FALSE,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'))
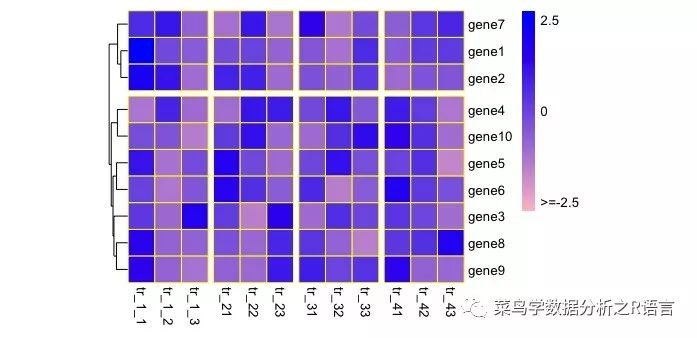
参数:gaps_row/gaps_col、cutree_rows/cutree_cols和treeheight_row/treeheight_col
cutree_rows按聚类分割,如cutree_rows=2,把基因表达量聚类分成2类;gaps_col=c(3,6,9)不能聚类,把重复都分开。gaps_XX对行或列进行分割,就不应对相应的行或列进行聚类;treeheight_row参数改变聚类的支长长度:
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend=FALSE,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'),cutree_rows = 2,gaps_col = c(3,6,9),treeheight_row = 10)
参数:annotation_row/annotation_col、annotation_colors、annotation_legend和annotation_names_row/annotation_names_col
利用annotation_col参数,给各个处理添加一个颜色标签;
利用annotation_colors对标签的颜色进行修改;
利用annotation_legend设置是否显示标签注释条;
利用annotation_names_col设置是否显示标签名称。
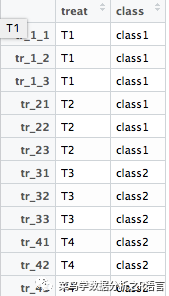
>annotation_col=data.frame(treat=factor(rep(paste0('T',1:4),each=3)),class=factor(rep(paste0('class',1:2),each=6)))
>ann_color=list(a=c(T1='yellow',T2='#757083',T3='firebrick',T4='#66A61E'),b=c(class1='blue',class2='#1B9E77'))
> row.names(annotation_col)=colnames(data)
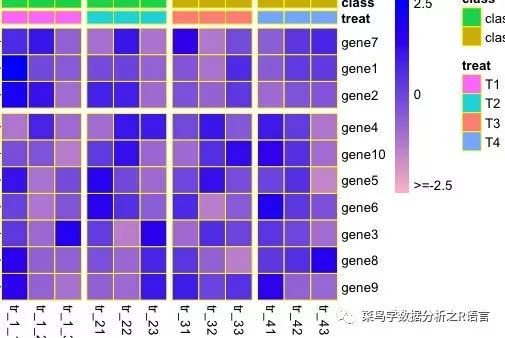
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'),cutree_rows = 2,gaps_col = c(3,6,9),treeheight_row = 10,annotation_col=annotation_col,annotation_legend=TRUE,annotation_colors=ann_color,annotation_names_col=TRUE)
运行过程中产生数据与图:
annotation_col:
参数:display_numbers、number_format、number_color和fontsize_number
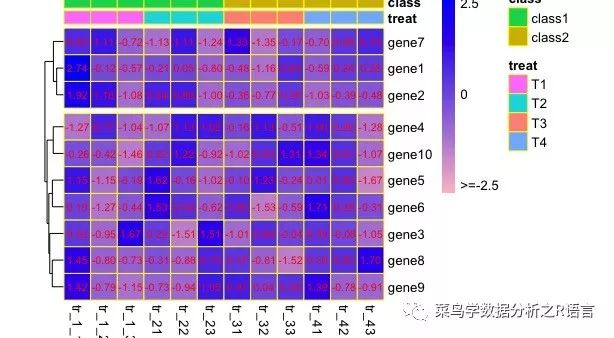
利用display_numbers参数可以在每个单元框内显示每个方框对于的数据,其中有三个选项,TRUE、FALSE以所对应的数据,如果设置display_numbers=T,这显示做了均一化的数据(如果之前使用过scale参数),设置display_numbers=data,则表示为直接显示原始数据,即可直接显示出RPKM值在单元格中;
number_color顾名思义就是这是设置显示数据的颜色了
fontsize_number则为显示每个数据的大小;
利用number_format可以设置保留小数位数或者字符串格式(如%.2f),但仅有在display_numbers=T时才能使用,很鸡肋,因此不建议使用该参数,而我们一般是直接显示RPKM值,所以我们需要之前对数据集进行保留小数处理,不然数据显示会超出单元格
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'),cutree_rows = 2,treeheight_row = 10,annotation_col=A,annotation_legend=TRUE,annotation_colors=ann_color,annotation_names_col=TRUE,display_numbers = TRUE,number_color = 'red',fontsize_number = 8,number_format = "%.2f")
运行结果如下:
 参数:show_rownames/show_colnames、fontsize_col/fontsize_row、fontsize和main
参数:show_rownames/show_colnames、fontsize_col/fontsize_row、fontsize和main
show_rownames表示是否显示gene名称,用逻辑值设置,fontsize_col设置横坐标名称的大小,fontsize则是设置所有除主图以外的标签的大小,利用main设置热图的名称,如:
>pheatmap(data,border_color='yellow',color=colorRampPalette(c('pink','blue'))(100),scale='row',cluster_cols = FALSE,cellwidth = 20,cellheight = 20,legend_breaks = c(-2.5,0,2.5),legend_labels = c('>=-2.5','0','2.5'),cutree_rows = 2,treeheight_row = 10,annotation_col=A,annotation_legend=TRUE,annotation_colors=ann_color,annotation_names_col=TRUE,display_numbers = TRUE,number_color = 'red',fontsize_number = 8,number_format = "%.2f",show_rownames = FALSE,fontsize_col = 15,fontsize=5,main = "heatmap test 2")
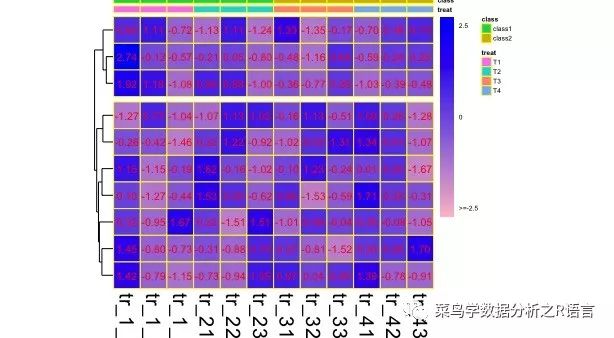
看完上述内容,你们掌握Pheatmap怎样绘制热图的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注行业资讯频道,感谢各位的阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/153162.html