
本文将详细解释Mysql百万级数据迁移的实例分析。边肖觉得挺实用的,就分享给大家参考。希望你看完这篇文章能有所收获。
如果有这样的场景,就开发一个小程序,利用“双十一”活动的火爆,一个月后就迅速积累了一百多万用户。我们在小程序的页面上增加了收集formid的埋点,给微信用户发送模板消息通知。
随着数据量的增加,之前使用的服务器空间开始有点不足。最近写了一个专门为小程序后台开发设计的新框架,所以想把原来的数据迁移到新系统的数据库中。买了4核8G机,开始数据迁移。以下是迁移过程的简单记录。
方案选择
mysqldump迁移在正常的开发中,我们经常使用数据备份迁移的方法,用mysqldump工具导出一个sql文件,然后将sql导入到新的数据库中,完成数据迁移。
实验表明,通过mysqldump将一个百万级的数据库导出到一个sql文件需要几分钟的时间。导出的sql文件大小约为1G,然后通过scp命令将1G sql文件复制到另一台服务器需要几分钟。通过source命令将数据导入新服务器的数据库。我跑了一晚上没有导入数据,cpu满了。
脚本迁移
通过命令行直接操作数据库是一种方便的数据导出和导入方式,但在数据量较大时,这种方式往往很耗时,并且需要较高的服务器性能。如果数据迁移的时间要求不是很高,可以尝试编写脚本来迁移数据。虽然没有实际尝试,但我想过大概有两种脚本方案。
第一种方式是在迁移目标服务器上运行迁移脚本,远程连接源数据服务器的数据库,通过设置查询条件分块读取源数据,读取后写入目标数据库。这种迁移方式的效率可能比较低,数据的导出和导入相当于一个同步的过程,需要等到读完再写。如果查询条件设计合理,也可以通过多线程启动多个迁移脚本,达到并行迁移的效果。
第二种方式,可以结合redis构建“生产与消费”的迁移方案。作为数据生产者,源数据服务器可以在源数据服务器上运行多线程脚本,并行读取数据库中的数据,并将数据写入redis队列。作为使用者,目标服务器还在目标服务器上运行多线程脚本,远程连接到redis,并行读取redis队列中的数据,并将读取的数据写入目标数据库。与第一种方法相比,这种方法是一种异步方案。数据导入和数据导出可以同时进行。通过使用redis作为数据传输站,效率将大大提高。
在这里,您还可以使用go语言编写迁移脚本。利用其原生并发性,可以达到并行迁移数据的目的,提高迁移效率。
文件迁移
第一种迁移方案的效率太低,第二种迁移方案的编码成本相对较高。通过对比分析网上找到的数据,最终选择了mysql。
选择dataintooutfilefile.txt、loaddatainfefilefile . txt totalable命令,以导入和导出文件的形式完成数百万数据的迁移。
迁移过程
导出源数据库中的数据文件
选择* from DC _ MP _ fansintooutfile '/data/fans . txt ';将数据文件复制到目标服务器
ar:false">zip fans.zip /data/fans.txtscp fans.zip root@ip:/data/
在目标数据库导入文件
unzip /data/fans.zipload data infile '/data/fans.txt' into table wxa_fans(id,appid,openid,unionid,@dummy,created_at,@dummy,nickname,gender,avatar_url,@dummy,@dummy,@dummy,@dummy,language,country,province,city,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy);
按照这么几个步骤操作,几分钟内就完成了一个百万级数据表的跨服务器迁移工作。
注意项
-
mysql安全项设置
在mysql执行load data infile和into outfile命令都需要在mysql开启了secure_file_priv选项, 可以通过show global variables like ‘%secure%’;查看mysql是否开启了此选项,默认值Null标识不允许执行导入导出命令。
通过vim /etc/my.cnf修改mysql配置项,将secure_file_priv的值设置为空:
[mysqld] secure_file_priv=''
则可通过命令导入导出数据文件。
-
导入导出的数据表字段不对应
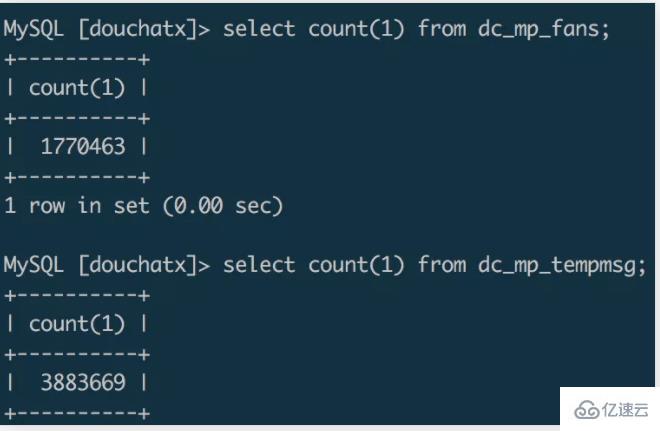
上面示例的从源数据库的dc_mp_fans表迁移数据到目标数据库的wxa_fans表,两个数据表的字段分别为:dc_mp_fans
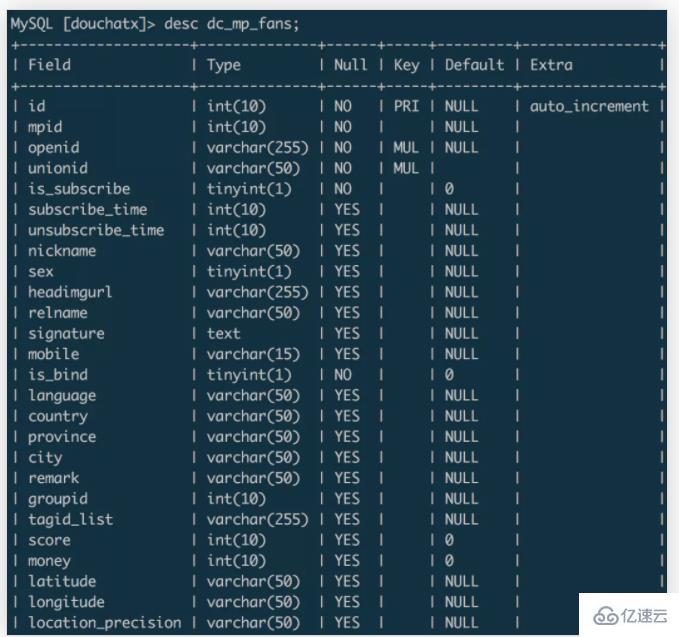

wxa_fans
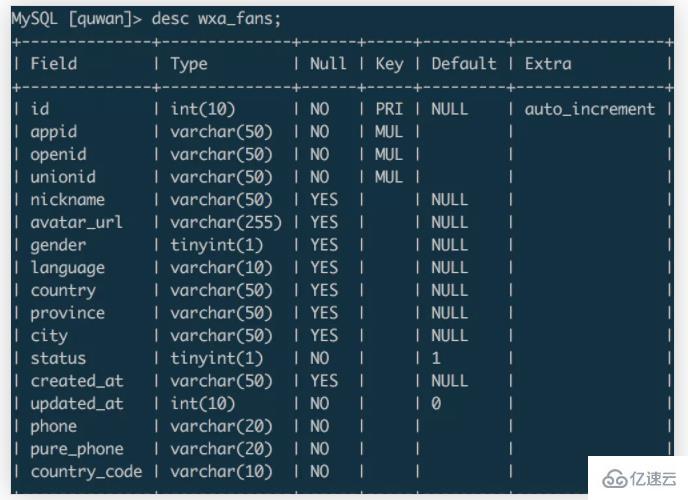
在导入数据的时候,可以通过设置字段名来匹配目标字段的数据,可以通过@dummy丢弃掉不需要的目标字段数据。
关于“Mysql百万级数据迁移的示例分析”这篇文章就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/153415.html