
RNN如何训练和预测时间序列信号,针对这个问题,本文详细介绍了相应的分析和解决方法,希望能帮助更多想要解决这个问题的小伙伴找到更简单、更容易的方法。
在上一期中,我们用RNN做了一个简单的手写分类器,
今天,让我们学习RNN如何训练和预测时间序列信号,如股价、温度、脑电波等。
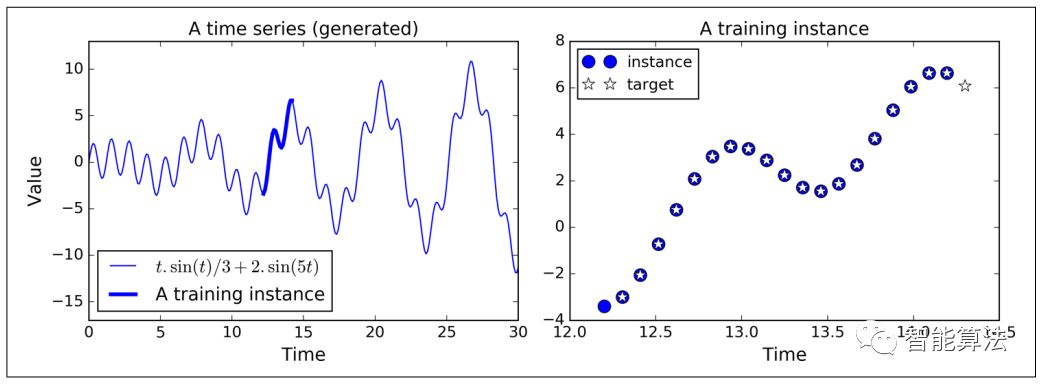
每个训练样本从时间序列信号中随机选择20个连续值,训练样本的对应目标是在下一个时间方向上移动一步的20个连续值,即除了最后一个值之外,前面的值与训练样本的最后19个值相同的序列。下图:

首先,我们创建一个RNN网络,它包括100个循环神经元。因为训练样本的长度是20,我们将其扩展为20个时间段。每个输入包含一个特征值(当时的值)。同样,目标也包含20个输入。代码如下,与前一个类似:
n步=20
n_inputs=1
n_neurons=100
n_outputs=1
X=tf.placeholder(tf.float32,[无,n_steps,n_inputs])
y=tf.placeholder(tf.float32,[None,n_steps,n_outputs])
cell=TF . contrib . rnn . basicrncell(num _ units=n _ neurons,activation=tf.nn.relu)
Outputs,States=TF.nn.dynamic _ rnn (cell,x,dtype=TF.float32)每时每刻,我们都有一个大小为100的输出向量,但实际上,我们需要的是一个输出值。最简单的方法是用Out putProjectionWrapper包装循环神经元。包装器像一个循环神经元一样工作,但叠加了其他功能。例如,它在循环神经元的输出端增加了线性神经元的全连接层(这不影响循环神经元的状态)。所有完全连接的层神经元共享相同的权重和偏差。下图:
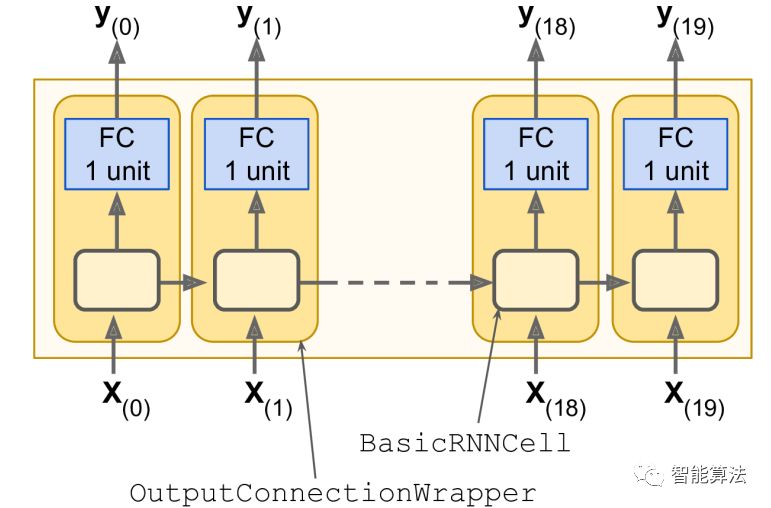
包裹一个循环神经元非常简单。只需微调前面的代码,将基本单元格转换为输出项目包装器,如下所示:
cell=TF . contrib . rnn . outputprojectionwrapper(
TF . contrib . rnn . basicrncell(num _ units=n _ neurons,activation=tf.nn.relu),
Output_size=n_outputs)到目前为止,我们可以定义损失函数。就像我们以前做回归一样,我们在这里使用均方误差。接下来,创建另一个优化器,并在此选择Adam优化器。如何选择优化器,参见上一篇文章:深度学习算法(第5期)——深度学习中的优化器选择。
学习率=0.001
损耗=tf.reduce_mean(tf.square(输出- y))
optimizer=TF . train . adamotimizer(learning _ rate=learning _ rate)
training _ op=optimizer.minimize(损失)
init=TF . global _ variables _ initializer()下一步是执行阶段:
n _迭代=10000
批处理大小=50
和tf一起。会话()作为会话:
init.run()
对于范围内的迭代(n_iterations):
X_batch,y_batch=[.] #获取下一个训练批次
sess.run(training_op,feed_dict={X: X_batch,y: y_batch})
如果迭代% 100==0:
MSE=loss . eval(feed _ dict={ X : X _ batch,y: y_batch})
打印(迭代,' \ tmse: ',mse)的输出结果如下:
0 MSE: 379.586
100毫秒: 14.58426
200 MSE: 7.14066
300 MSE: 3.98528
400 MSE: 2.00254
[.]一旦模型经过训练,就可以用来预测:
X_new=[.] #新序列
Y _ pred=sessions.run (outputs,feed _ dict={x:x _ new})下图显示了使用上述代码进行1000次迭代训练后模型的预测结果: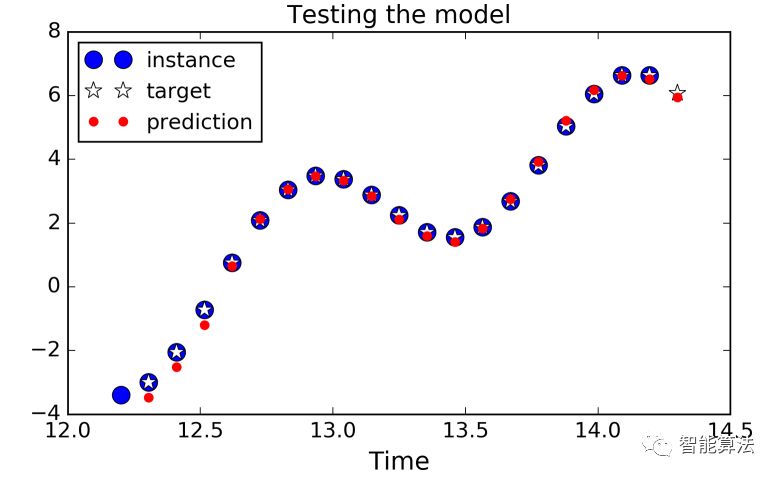
虽然使用OutputProjectionWrapper是将RNN的输出序列减少到一个值的最简单的方法,但它不是最有效的。这里有一个技巧可以更有效:首先,将RNN输出的形状从[batch_size,n_steps,n_neurons]转换为[batch_size * n_steps,n_neurons],然后输出一个[batch_size * n_steps,N_outputs],最后将张量改为[batch_size,n_steps,n_outputs]。如下所示: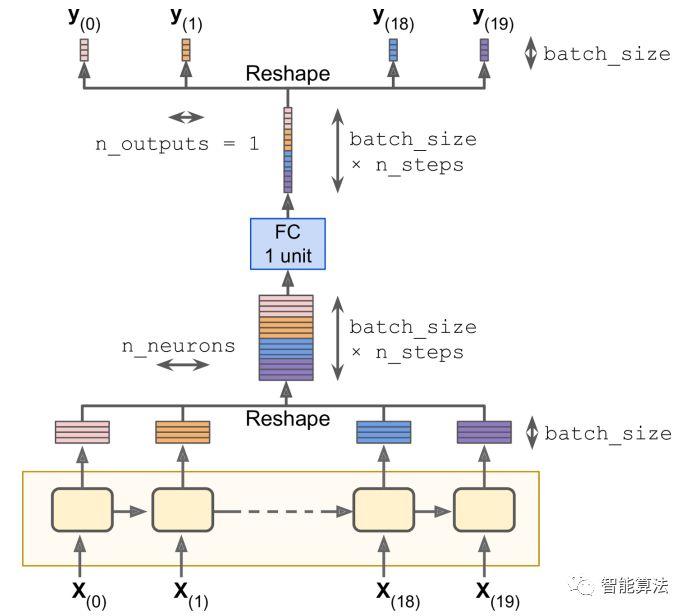
实施这个计划并不难。不需要输出项目包装器,只需要基本单元,如下所示:
cell=TF . contrib . rnn . basicrncell(num _ units=n _ neurons,activation=tf.nn.relu)
Rnn _ outputs,States=TF.nn.dynamic _ rnn (cell,x,dtype=TF.float32)然后,我们刷新结果,全连接层,然后按如下方式刷新它们:
stacked _ rnn _ outputs=TF . resform(rnn _ outputs,[-1,n_neurons])
堆叠输出=完全连接(堆叠rnn输出,n输出,
激活_ fn=无)
输出=TF。整形(stacked _ outputs,[-1,n _ steps,n _ outputs])下一个代码与上一个代码相同。因为这次只使用了一个全连接层,所以速度比以前快很多。
关于RNN如何训练和预测时间序列信号的问题的答案将在这里分享。希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/154128.html