
本文主要讲解“什么是Python矩和矩母函数”。感兴趣的朋友不妨看看。本文介绍的方法简单、快速、实用。让边肖学习一下“什么是Python矩和矩母函数”!
斜度
值得考虑的是,期望和方差是否足以描述一个分布?如果答案是肯定的,那么我们不需要寻找其他描述性的量。事实上,这两种描述不足以完全描述一个分布。
我们看两个分布,一个是指数分布:
f(x)={ ex0 ififx0x0f(x)={ exifx00 ifx 0
它的期望值是E(x)=1E(x)=1,方差是Var(x)=1Var(x)=1。
我们用Y=2-X得到一个新的随机变量及其分布:
f(y)={ E2-y0ifify2y2f(y)={ E2-yify20if y2
密度曲线与原始密度曲线关于直线X=1对称,具有与原始分布相同的期望值和方差。期望值为E(x)=1E(x)=1,方差为Var(x)=1Var(x)=1。
我们绘制了两种分布的密度曲线,如下图:所示。
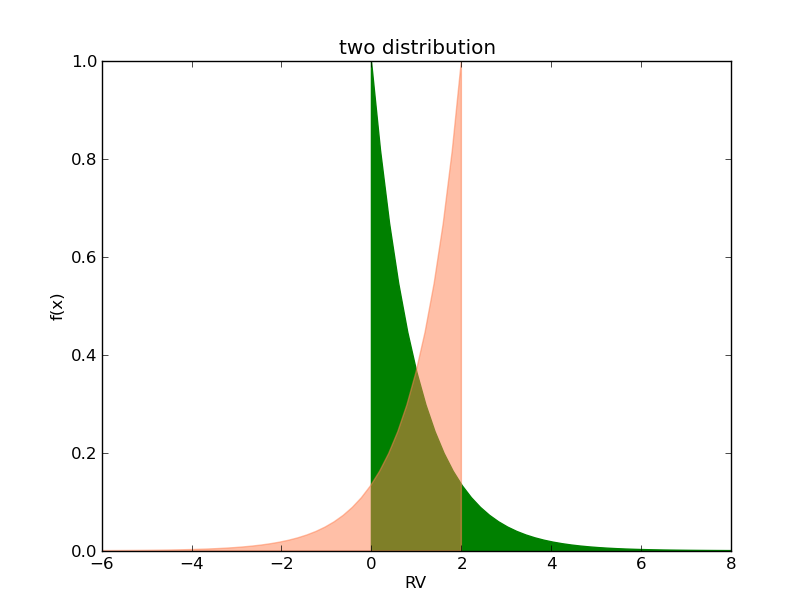

可以看出,即使期望值和方差不变,两条分布曲线也明显不同。第一条曲线下的区域向左倾斜,而第二条曲线向右倾斜。为了表达这种分布特征,我们引入了一个新的描述量,偏斜度。定义为:
偏斜(X)=E[(X)3]偏斜(X)=E[(X)3]
在上述两个分布中,第一条曲线向左倾斜,斜率分别为2。另一条曲线的斜率是-2。显然,斜率的不同会带来分布的巨大差异(即使期望和方差相同)。
绘制程序如下
from scipy . stats import texponipimportumpunyasnpimportmatplotlib . pyplotasplt
rv=指数(标度=1)
x1=np.linspace(0,20,100)
x2=np.linspace(-18,2,100)
y1=rv.pdf(x1)
y2=rv.pdf(2-x2)
plt.fill_between(x1,y1,0.0,color='green ')
plt.fill_between(x2,y2,0.0,color='coral ',alpha=0.5)
plt.xlim([-6,8])
plt.title('twodistribution ')
plt.xlabel('RV ')
plt.ylabel('f(x)')
遵守方差和斜率的定义。
Var(X)=E[(X)2]Var(X)=E[(X)2]
偏斜(X)=E[(X)3]偏斜(X)=E[(X)3]
是x的函数的期望,它们之间唯一的区别就是函数的形式,也就是(x ) (x )的幂不同。方差是2的幂,斜率是3的幂。
所有上述描述符都可以归类为一族描述符“矩”。与方差和斜率类似,它们是(x ) (x )幂的期望值,称为中心矩。E [(x ) k] e [(x ) k]称为k阶中心矩,表示为kk,其中k=2,3,4,
另一个是关于原点的时刻,是对XX力量的期待。E[Xk]E[Xk]称为K阶原点矩,表示为'kk ',其中k=1,2,3,
预期一阶原点矩:
E(X)=E(X1)E(X)=E(X1)
矩
,除了中心、离散程序和斜率的特征外,高阶矩还可以描述分布的其他特征。矩在统计学中起着重要的作用。例如,参数估计的一个重要方法是使用矩。然而,根据力矩的定义,我们需要期望不同的x次幂。这个过程涉及到一个复杂的集成过程,并不容易。矩也诞生了矩母函数,它是求解矩的有力武器。
在理解矩母函数之前,我们先来复习一下幂级数。幂级数是不同阶次的幂(如1,x,x2,x3.1,x,x2,x3
...)的加权总和:
∑i=1+∞aixi∑i=1+∞aixi
aiai是一个常数。
幂级数是数学中的重要工具,它的美妙之处在于,解析函数都可以写成幂级数的形式,比如三角函数sin(x)sin(x)可以写成:
sin(x)=x−x33!+x55!−x77!+...sin(x)=x−x33!+x55!−x77!+...
将解析函数分解为幂级数的过程,就是泰勒分解(Taylor)。我们不再深入其具体过程。xnxn是很简单的一种函数形式,它可以无限次求导,求导也很容易。这一特性让幂级数变得很容易处理。将解析函数写成幂级数,就起到化繁为简的效果。
(幂级数这一工具在数学上的用途极其广泛,它用于数学分析、微分方程、复变函数…… 不能不说,数学家很会活用一种研究透了的工具)
如果我们将幂级数的x看作随机变量X,并求期望。根据期望可以线性相加的特征,有:
E(f(X))=a0+a1E(X)+a2E(X2)+a3E(X3)+...E(f(X))=a0+a1E(X)+a2E(X2)+a3E(X3)+...
我们可以通过矩,来计算f(X)的期望。
另一方面,我们可否通过解析函数来获得矩呢?我们观察下面一个指数函数,写成幂级数的形式:
etx=1+tx+(tx)22!+(tx)33!+(tx)44!...etx=1+tx+(tx)22!+(tx)33!+(tx)44!...
我们再次将x看作随机变量X,并对两侧求期望,即
E(etX)=1+tE(X)+t2E(X2)2!+t3E(X3)3!+t4E(X4)4!...E(etX)=1+tE(X)+t2E(X2)2!+t3E(X3)3!+t4E(X4)4!...
即使随机变量的分布确定,E(etX)E(etX)的值还是会随t的变化而变化,因此这是一个关于t的函数。我们将它记为M(t)M(t),这就是矩生成函数(moment generating function)。对M(t)M(t)的级数形式求导,并让t等于0,可以让高阶的t的乘方消失,只留下E(X)E(X),即
M′(0)=E(X)M′(0)=E(X)
即一阶矩。如果继续求高阶导,并让t等于0,可以获得高阶的矩。
M(r)(0)=E(Xr)M(r)(0)=E(Xr)
有趣的是,多次求导系数正好等于幂级数系数中的阶乘,所以可以得到上面优美的形式。我们通过幂级数的形式证明了,对矩生成函数求导,可以获得各阶的矩。相对于积分,求导是一个容易进行的操作。
矩生成函数的性质
矩生成函数的一面是幂级数,我们已经说了很多。矩生成函数的另一面,是它的指数函数的解析形式。即
M(t)=E[etX]=∫∞−∞etxf(x)dxM(t)=E[etX]=∫−∞∞etxf(x)dx
在我们获知了f(x)的具体形式之后,我们可以利用该积分获得矩生成函数,然后求得各阶的矩。当然,你也可以通过矩的定义来求矩。但许多情况下,上面指数形式的积分可以使用一些已有的结果,所以很容易获得矩生成函数。矩生成函数的求解矩的方式会便利许多。
矩生成函数的这一定义基于期望,因此可以使用期望的一些性质,产生有趣的结果。
性质1 如果X的矩生成函数为$MX(t)],且[$Y=aX+b$MX(t)],且[$Y=aX+b,那么
MY(t)=eatMX(bt)MY(t)=eatMX(bt)
(将Y写成指数形式的期望,很容易证明该结论)
性质2 如果X和Y是独立随机变量,分别有矩生成函数MX,MYMX,MY。那么对于随机变量Z=X+YZ=X+Y,有
MZ(t)=MX(t)MY(t)MZ(t)=MX(t)MY(t)
(基于独立随机变量乘积的期望,等于随机变量期望的乘积)
练习:
推导Poisson分布的矩生成函数
到此,相信大家对“Python矩与矩生成函数是什么”有了更深的了解,不妨来实际操作一番吧!这里是网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/154657.html