
本文主要介绍“风暴的设计理念是什么”。在日常操作中,相信很多人对于Storm的设计思路是什么都有疑问。边肖查阅了各种资料,整理出简单易用的操作方法,希望能帮你解答“Storm的设计理念是什么”的疑惑!接下来,请和边肖一起学习!
00-1010不同于传统的离线批量操作(对大量数据集的操作)。实时处理,说白了就是对一条数据/记录进行操作,所有这些操作都是汇总的(统计到现在的总和)。
实时计算概述
有界:有界
离线计算面临的操作数据是有界的,无论是1G、1T、1P、1EB还是1NB。
数据的有界必然导致计算的有界。
无界:
实时计算面对的是源源不断的流水般的运行数据,没有极限。
数据的XXX必然导致计算的XXX。来自Flink官网的解释:
首先,2个2typesofdatasets
连续取消卸载:无限重复数据集
有界:有限的、不可变的数据集
第二,2个2typesofexecutionmodels
产生了流:执行连续延迟的处理
batch : processing that sexecuted and unstocompletenessinanniteamount of
时间,释放计算资源当新棚
实时计算与离线计算比较
三个计算中心
离线批处理
准实时流量计算中心
实时流计算
3.大型计算引擎
用户交互计算引擎
图形计算引擎
机器学习计算引擎
大数据处理的6大问题
ApacheStorm是一个开源的实时数据处理框架,类似于Twitter的Hadoop。它最初是由BackType开发的,后来BackType被Twitter收购,使用Storm作为Twitter的实时数据分析系统。
Storm可以实现对高频数据和大规模数据的实时处理。
根据官网数据,暴风一个节点一秒钟可以处理100字节的百万条消息(英特尔5645@2.4Ghz GHz CPU,24GB内存)。(也就是说,单个节点每秒处理大约95MB的数据)
官方网站:http://storm.apache.org
00-1010数据源
HADOOP处理HDFS的TB级数据(历史数据),而STORM处理一些实时添加的新数据(实时数据)。
处理过程
HADOOP分为MAP阶段和REDUCE阶段。STORM是由用户定义的流程。流程可以包含多个步骤,每个步骤可以是一个数据源(SPOUT)或一个处理逻辑(bolt)。
结束还是不结束?
HADOOP终于要结束了。STORM没有结束状态。在最后一步,它停止在那里,从头开始,直到新的数据进来。
加工速度
HADOOP旨在处理HDFS的TB级数据,处理速度较慢。STORM只需要处理一定量的新增数据,可以快速完成。
适用场景
在处理批量数据时使用HADOOP,但不注重时效性。在处理一些新数据的时候使用STORM,要注意时效性。
Storm简介
风暴是对流流的抽象,对流流是不间断的流
Storm将流中的元素抽象成元组。元组是值——valuelist的列表。列表中的每个值都有一个名称,该值可以是基本类型、字符类型、字节数组等。当然,它也可以是其他可序列化的类型。
Storm认为每个流都有一个流源,也就是原始元组的源,所以称这个源为Spout。
有了源,即喷口,即流,如何处理流中的元组?流的状态转移称为bolt。bolt可以消耗任意数量的输入流。只要流方向指向螺栓,它也可以向其他螺栓发送新的流。这样,只要打开特定的喷口(喷嘴),从喷口流出的元组就被导向特定的螺栓,并且导入的流由螺栓处理,然后被导向其他螺栓或目的地。
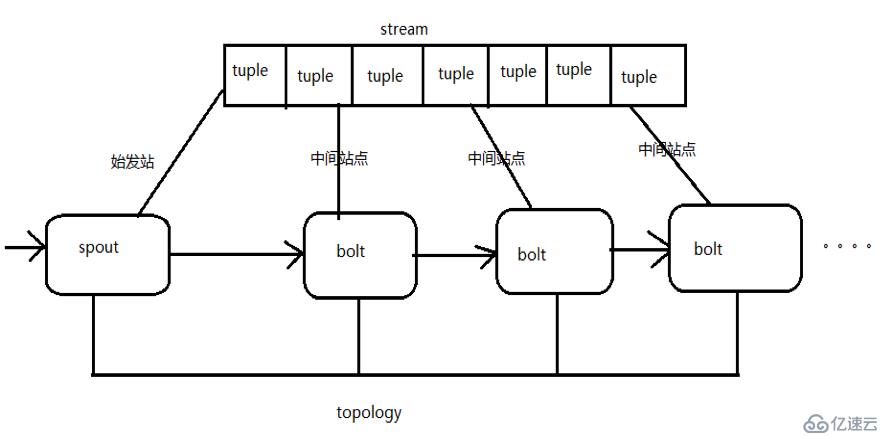

上述过程统称为拓扑或拓扑。拓扑是storm中最高层的抽象概念,可以提交给storm集群执行。拓扑是一个流转换图,其中每个节点都是一个sprut或bolt。图中的边表示bolt订阅的流。当sprut或bolt向流发送元组时,它会向订阅流的每个bolt发送元组(这意味着我们不需要手动拉管道,只要我们提前订阅,sprut就会将流发送到合适的bolt。
拓扑的每个节点都应该指定它发出的元组的字段名称,其他节点只能通过订阅该名称来接收处理。
至此,“Storm的设计理念是什么”的研究结束,希望能解决大家的疑惑。理论和实践的结合可以帮助你学得更好。去试试吧!如果你想继续学习更多的相关知识,请继续关注网站,边肖会继续努力,给大家带来更多实用的文章!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/156279.html