
本文介绍了JVM字符串常量池和字符串的实习方法。内容非常详细。感兴趣的朋友可以参考一下,希望对大家有所帮助。
在前一篇文章中已经详细解释了字符串的比较。本文基于字符串常量池的存储和使用intern方法引起的内存变化。
内容:字符串调用intern方法后进行比较会发生什么?
00-1010首先,通过面对面的考试,我们可以获得本文将要讨论的内容的呈现形式的图像:
Strings1=新闻字符串(' he ')新闻字符串(' llo ');
Strings2=新闻字符串(' h ')新闻字符串(' ello ');
string S3=S1 . intern();
string S4=S2 . intern();
system . out . println(S1==S3);
system . out . println(S1==S4);当您执行上述代码时,您会发现打印的结果都是真的。那么,为什么调用intern方法后不相等的字符串相等呢?让我们一步一步地分析底层实现。
面试题
实习生()方法的功能定义:
(1)如果当前字符串的内容存在于字符串常量池中(即equals()方法为真,即内容相同),则直接返回该字符串在常量池中的引用;
(2)如果当前字符串不在字符串常量池中,则在常量池中创建一个引用并指向堆中现有的字符串,然后返回常量池中的引用。
简单来说,intern方法就是判断字符串常量池中是否存在字符串,不存在就创建,存在就返回。
intern方法的作用
HotSpot中的字符串常量池函数是由一个StringTable类实现的,它是一个Hash表,默认大小和长度为1009。HotSpot虚拟机的每个实例中只有一个副本,由所有类共享。字符串常量由放置在StringTable上的字符组成。
在文章《面试题系列第5篇:JDK的运行时常量池、字符串常量池、静态常量池,还傻傻分不清?》中,我们专门介绍了字符串常量池的位置随着JDK版本的变化而变化,可以参考一下。
在JDK6及之前,字符串常量池被放在Perm Gen区域(方法区域)。StringTable的长度是固定的,长度是1009。当字符串过多时,会造成哈希冲突,导致链表过长,性能大大降低。此时,所有字符串常量(文字值)都放在字符串常量池中。
由于永久生成空间有限且固定,JDK6的存储方式很容易造成OutOfMemoryError。
当JDK7正在进行永久生成时,字符串常量池被放入堆中。此时,即使堆的大小是固定的,对于应用程序调优工作,也只需要调整堆的大小。
在JDK7中,字符串常量池不仅可以存储字符串常量,还可以存储字符串引用。也就是说,对堆中字符串的引用可以作为常量池的值存在。
00-1010了解以上基础理论后,我们将通过图文结合的形式,逐步演示串池化的过程和分类。以下示例基于JDK8版本进行分析和说明。
当我们用双引号声明一个字符串时:
Stringwechat='程序的新愿景';此时,双引号中的字符串将直接存储在字符串常量池中。
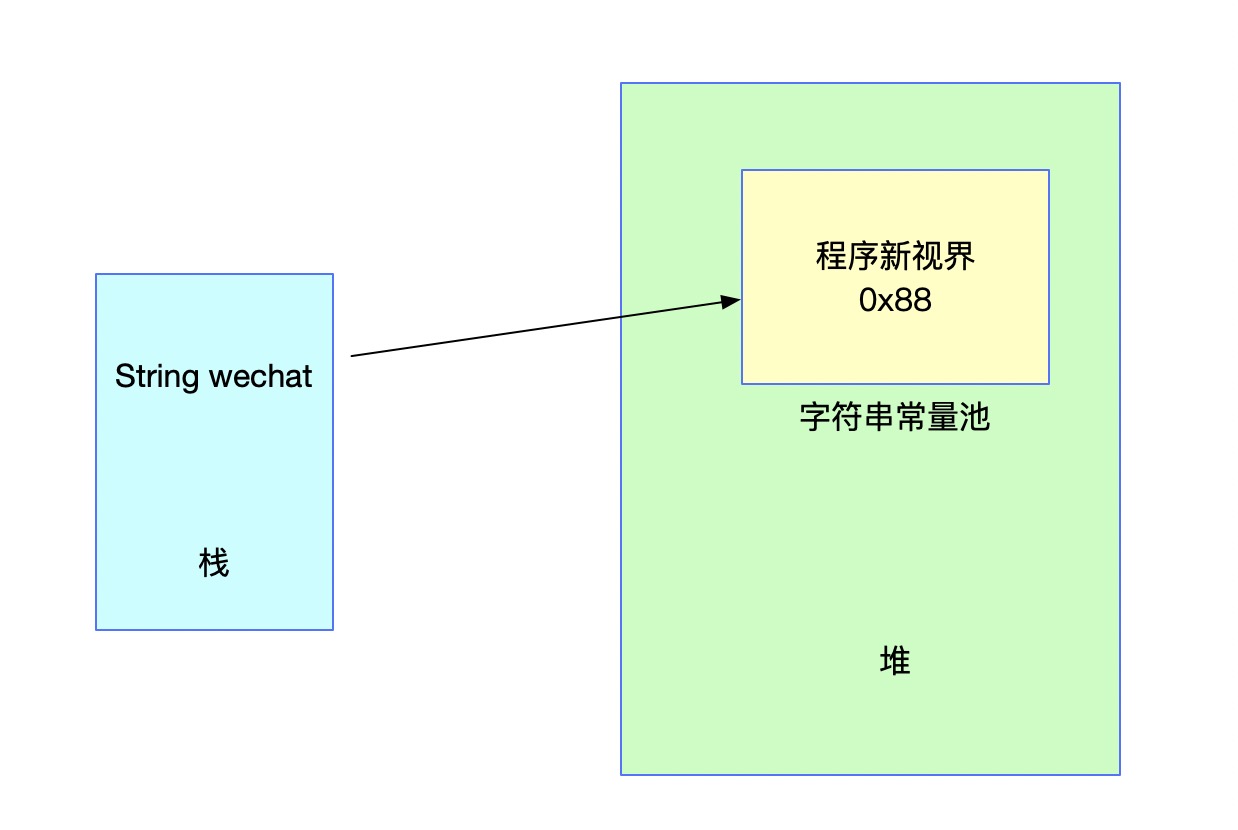

至于上面的存储结构,我们在之前的文章中已经提到过了,就不多解释了。让我们看看如果我们再次声明同一个字符串会发生什么。
Stringwechat='程序的新愿景';
Stringwechat1='程序的新愿景';在上面的代码中声明微信1时,会发现常量池中已经存在对应的字符串,所以不会重新创建,但是会将对应的引用返回给微信1。对应的结构图如下: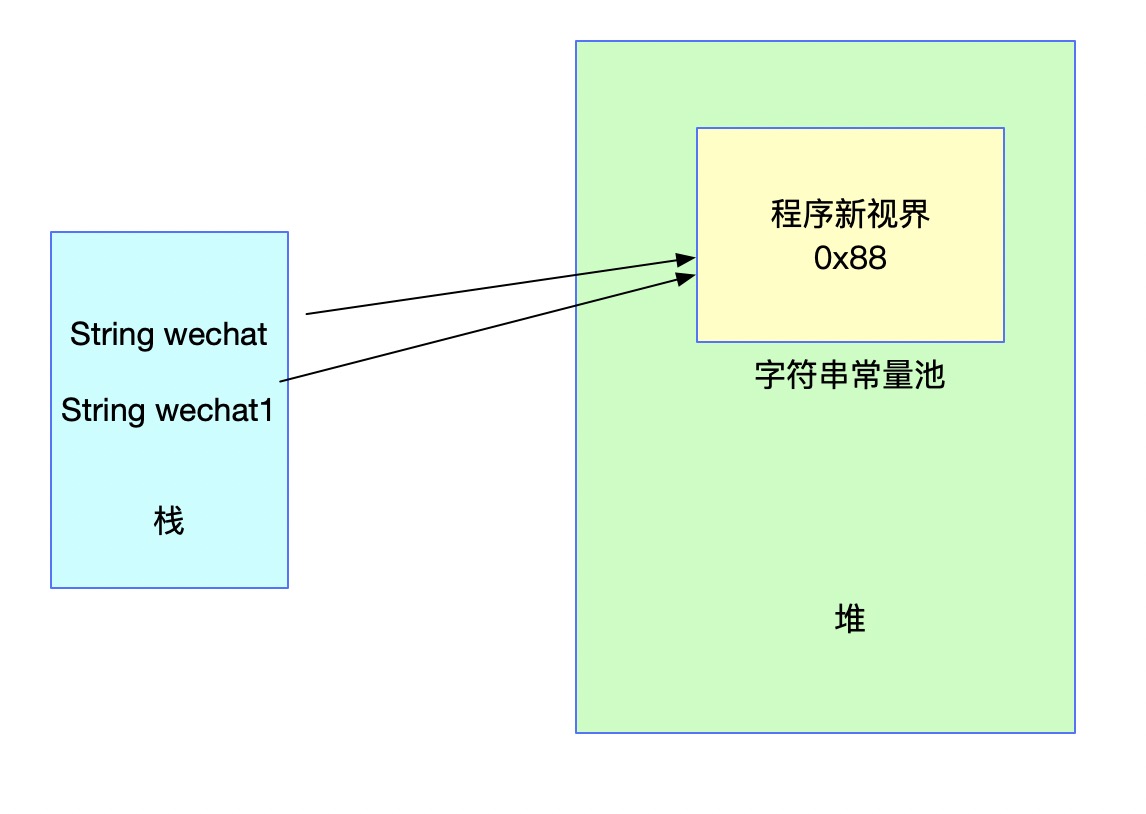 。
。
在这一点上,如果微信和微信1直接用双等号比较,肯定是相等的,因为它们的引用和字面值是一样的。
以上是直接双引号赋值的情况,所以如果对应字符串的进程是以new的形式创建的。
又是如何呢?前面文章已经讲到这分两种情况:常量池存在对应的值和不存在对应的值。
String wechat2 = new String("程序新视界");
如果存在对应的值,此时会先在堆中创建一个针对wechat2变量的对象引用,然后将这个对象引用指向字符串常量池中已经存在的常量。 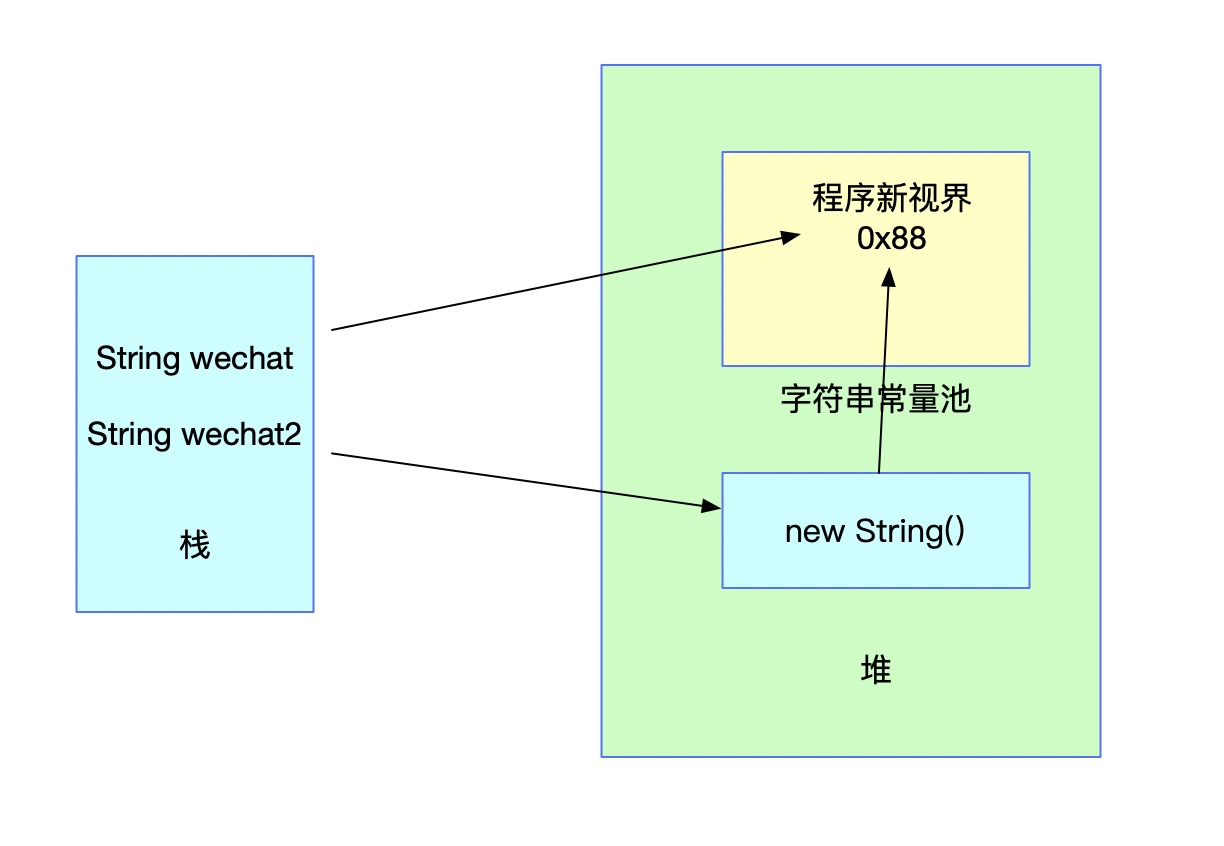
此时直接使用双等号比较wechat和wechat2变量肯定是不相等的,而通过equals方法进行对比字面值则是相等的。
另外一种情况就是通过new创建时,字符串常量池中并不存在对应的常量。这种情况会现在字符串常量池中创建一个字符串常量,然后再在堆中创建一个字符串,持有常量池中对应字符串的引用。并把堆中对象的地址返回给wechat2。最终效果图依旧如上图。
在此时,如果不是直接new字符串赋值,而是通过+号操作,情况就有所不同。
String s1 = "程序"; String wechat3 = new String(s1 + "新视界");
上述代码s1会存入常量池,而wechat3的值则由于JVM编译时采用了StringBuilder进行加号的拼接,只会在堆中创建一个String对象,并不会在常量池中存储对应的字符串。
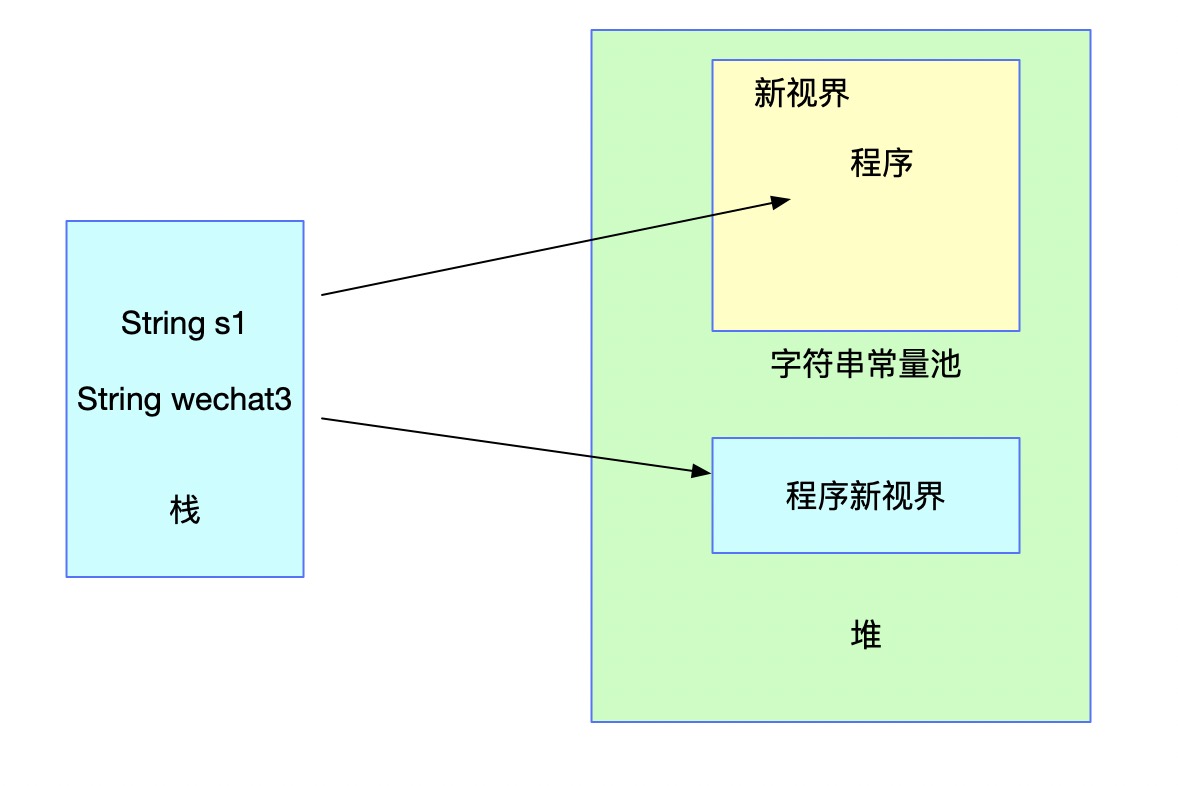
此时的情况已经涉及到我们面试题中创建字符串的情况了。那么,下面我们就通过intern方法进行池化操作,看看字符串常量池的具体变化。
还以上面的代码为例,此时wechat、wechat1、wechat2三个变量和wechat3直接用双等号比较肯定是不相等的。下面对wechat3进行intern池化处理。
String s1 = "程序"; String wechat3 = new String(s1 + "新视界"); wechat3 = wechat3.intern();
此时会发现wechat、wechat1两个变量与wechat3的值相等了。由于wechat和wechat1其实是一个,这里只以wechat和wechat3的比较为例来分析一下这个流程。
在没有调用intern方法之前内存的状态是下图(忽略掉s1部分)这样的:
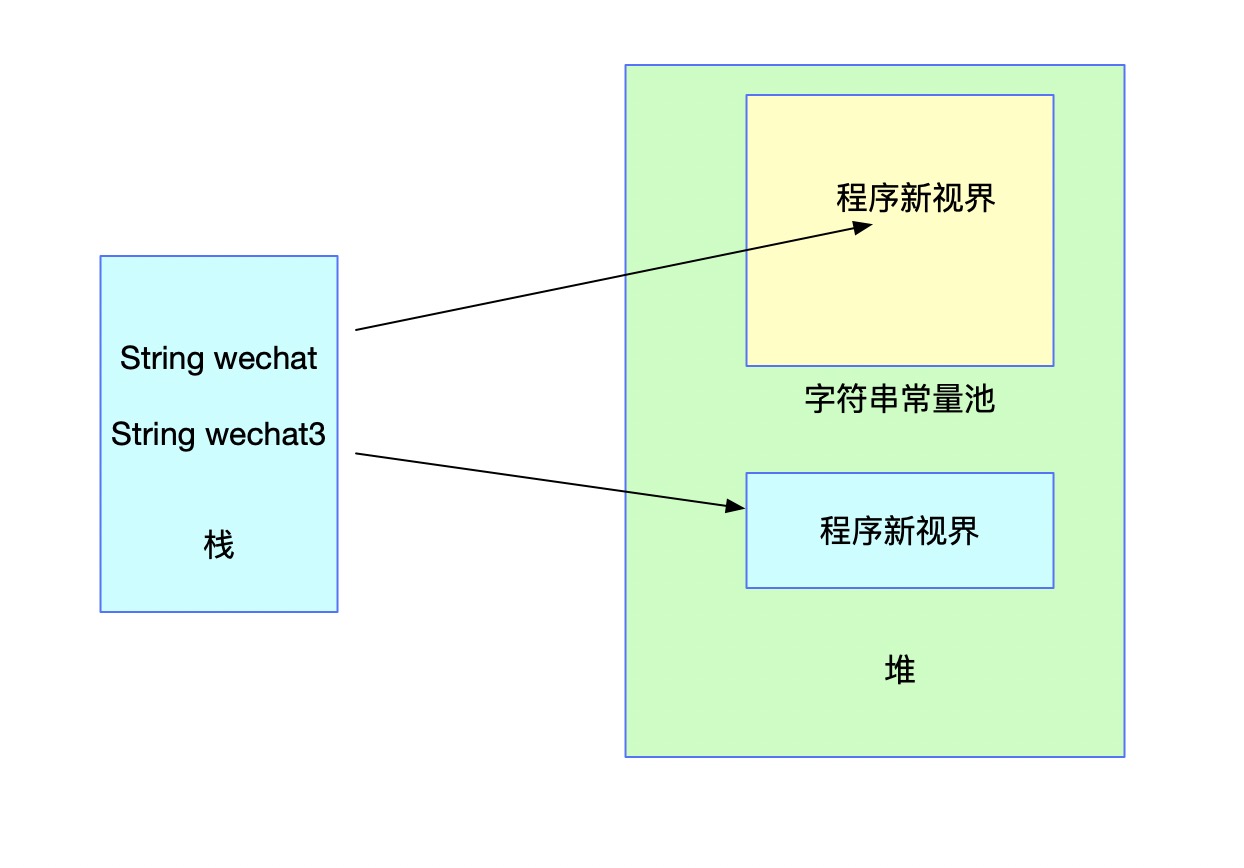
看上图它们的值不相等也就不奇怪了。下面对wechat3进行池化处理,并把池化的结果赋值给wechat3,就是上面的代码。内存结构会发生如下变化:

此时,再判断对应的两个值,因为引用和字面值全部相同,因此便相等了。具体intern的判断规则我们上面已经知道,如果常量池中存在对应的值,则直接返回引用。
那还有另外一种情况,就是常量池中不存在对应的值会是如何处理的呢?先看如下代码:
String s2 = "关注"; String wechat4 = new String(s2 + "公众号"); wechat4 = wechat4.intern();
在调用intern之前的操作我们前面已经说过,会在堆中创建一个String对象,而常量池中并不会存储一份,与wechat3的图一样。
此时常量池中并未存在对应的字符串,此时调用intern方法之后,内存结构如下:
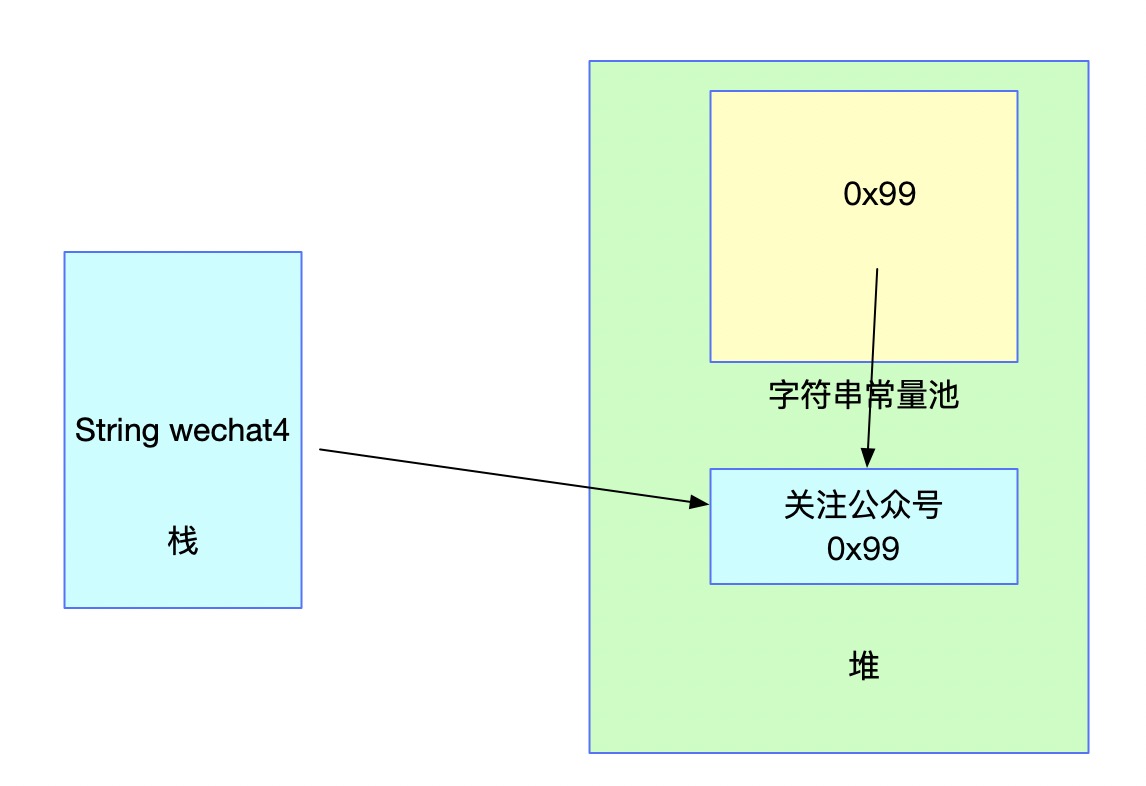
经intern方法之后,常量池中存了堆中对应字符串的引用。对照上面说的,JDK7及之后字符串常量池中可以存储引用了。
需要注意的是,当字符串常量池中并不存在对应字符串时,调用intern方法返回的地址为堆中的地址,对应图中的0x99。而wechat4本来地址指向的就是堆中的地址,因此不会发生变化。
此时如果再定义一个双引号赋值的wechat5,如下代码:
String s2 = "关注"; String wechat4 = new String(s2 + "公众号"); wechat4 = wechat4.intern(); String wechat5 = "关注公众号"; System.out.println(wechat4 == wechat5);
变量wechat5初始化时发现字符串常量池中已经存在了一个引用,那么wechat5会直接指向这个引用,也就是wechat5和wechat4一样,都指向内存中的String对象。 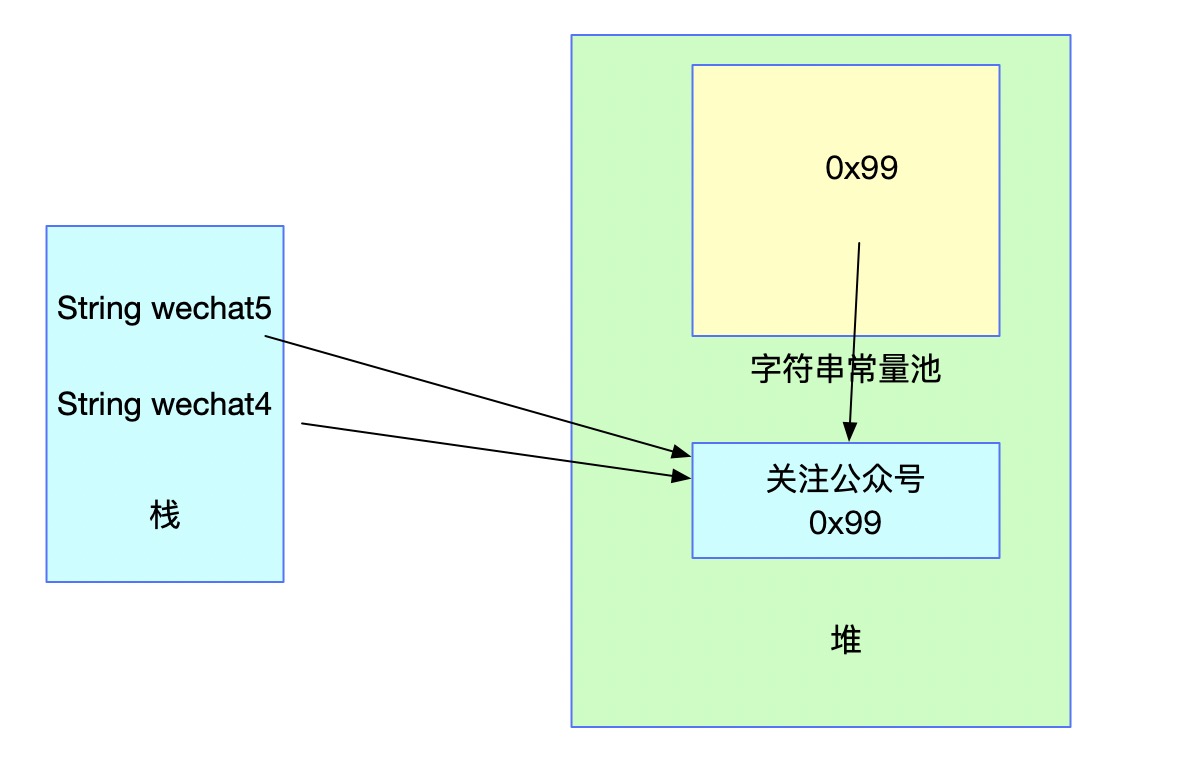
小结
上面这个演示实例时需要注意的重点是intern方法返回的引用地址。如果字符串常量池中已经存在对应的字符串时,此时返回的是字符串常量的地址【常量池中存储的是字符串】,如果字符串常量池中不存在对应的字符串,此时会把堆中的引用放在常量池对应的位置【常量池中存储的是堆中字符串的引用】,此时intern返回的是堆中字符串对应的引用。
搞清楚了上面的返回逻辑再看最初的代码:
String s1 = new String("he") + new String("llo");
String s2 = new String("h") + new String("ello");
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s4);
其中s1为堆中字符串“hello”的地址;s2为堆中另外一个“hello”字符串的地址。当s1.intern(),常量池中存储了s1的地址,此时s1.intern()返回的也是s1的地址,因此s1=s3,都是同一个地址嘛。
然后执行s2.intern(),此时常量池中已经有hello字符串,类型为引用且指向s1的地址,执行之后返回的便是s1的地址,赋值给s4,因此s1和s4也指向同一个地址,因此相等。
通过上面的更深层次的分析,想必大家对字符串常量、字符串常量池以及intern方法有了更加深刻的理解。
关于JVM字符串常量池及String的intern方法是什么样的就分享到这里了,希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/44219.html