
相信很多没有经验的人,对于如何通过Python抓取Tik Tok的热门视频,都是一窍不通的。因此,本文总结了出现问题的原因和解决方法,希望大家可以通过这篇文章来解决这个问题。
前言
相信大家都听过颤音的短视频,对它也不陌生吧?你可以看到大量的短视频,涵盖所有主要行业。我个人觉得Tik Tok有毒,不能不刷,时间是凌晨三四点。今天,我带你去抓取Tik Tok网页的视频数据!快速看一下。
1.系统分析网页的本质。
2.定期提取数据(难度)。
3.保存大量音频数据。
环境介绍:
python 3.6
pycharm
要求
是
00-1010 1.分析目标网页并确定要爬网的url路径和标头参数。
2.发送请求-请求模拟浏览器发送请求并获取响应数据。
3.解析数据-正则表达式。
4.保存数据-将其保存在目标文件夹中。


爬虫的一般思路
1、导入工具
base _ URL=' http://douyin . bm8.com.cn/d _ 1 . html '
标题={ 0
用户代理' : ' Mozilla/5.0(windowsnt 10.0;Win64x64)applebwebkit/537.36(KHTML,likeGecko)Chrome/83 . 0 . 4103 . 116 safari/537.36 ' }2、分析目标网页,确定爬取的url路径,headers参数
base _ URL=' http://douyin . bm8.com.cn/d _ 1 . html '
标题={ 0
用户代理' : ' Mozilla/5.0(windowsnt 10.0;Win64x64)applebwebkit/537.36(KHTML,likeGecko)Chrome/83 . 0 . 4103 . 116 safari/537.36 ' }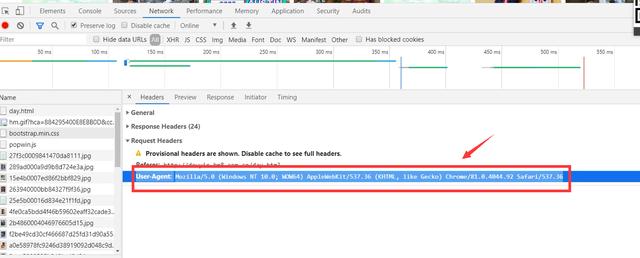
3、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response=requests . get(URL=base _ URL,headers=headers)
html _ data=response . text4、解析数据 -- 正则表达式
pattern=re.compile(' onclick=' open 1 \(\ '(。*?)\',\'(.*?)\',\'\'\)')
结果=pattern.findall(html_data)
打印(结果)5、构建一个for循环
对于范围(8,10):
打印('======================================'。格式(页面))。
#1.分析目标网页并确定要爬网的url路径和headers参数。
base _ URL=' http://dou yin . bm8.com.cn/d _ { }。html。格式(页面)
标题={ 0
用户代理' : ' Mozilla/5.0(windowsnt 10.0;Win64x64)applebwebkit/537.36(KHTML,likeGecko)Chrome/83 . 0 . 4103 . 116 safari/537.36 ' }6、处理文件名非法字符
defchange_title(标题):
模式=re.compile(r'[\/\\\:\*\?\'\\\|]')#'/\:*?7、保存数据 -- 保存在目标文件夹中
fortitle,urlinresult:
#请求颤音视频数据。
data=requests.get(url=url,headers=headers)。内容
新标题=更改标题(标题)
with open(' videos \ \ ' new _ title . MP4 ',mode='wb')asf:
写(数据)
打印('保存的: ',标题)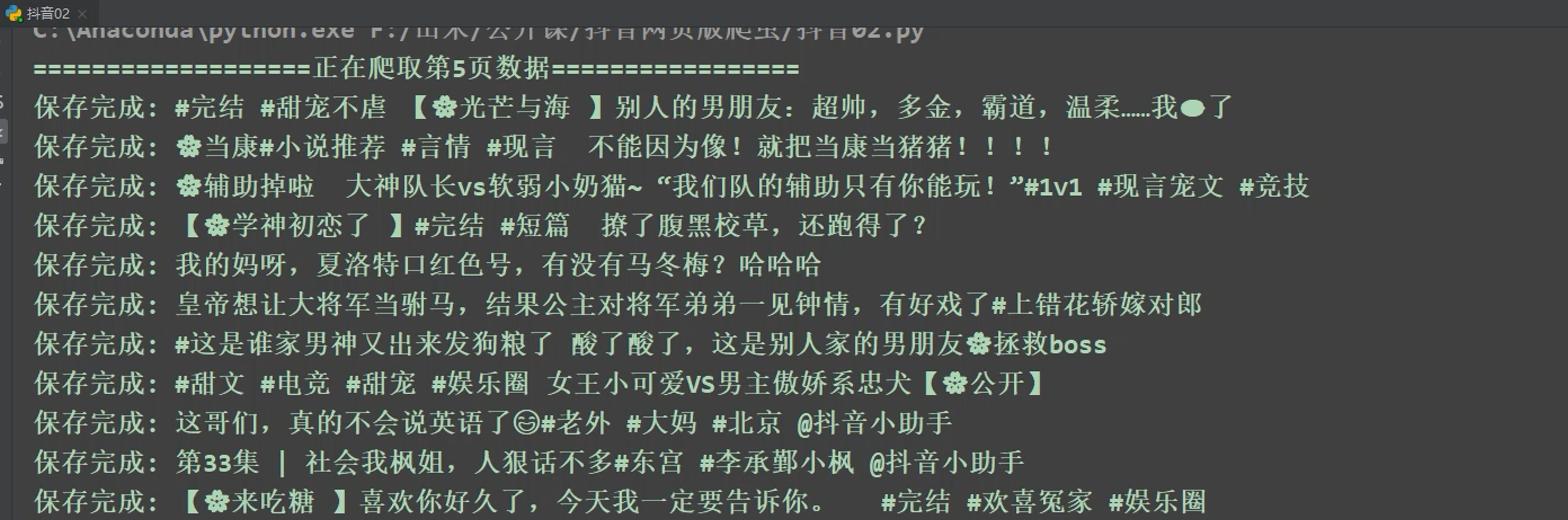
看完以上,你知道如何通过Python抓取Tik Tok的热门视频吗?如果您想学习更多技能或了解更多相关内容,请关注行业资讯频道。感谢阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/49009.html