
相信很多没有经验的人对于如何用Python爬小红书都是一窍不通的。因此,本文总结了出现问题的原因和解决方法,希望大家可以通过这篇文章来解决这个问题。
小红书
首先让我们打开大家之前配置的charles。
让我们简单的抓取一下小红书小程序(注意这是一个小程序,不是一个app)。
我没有选择app的原因是小红书的App有点难。我参考了网上的一些想法,选择了一个小程序。
1、通过charles抓包对小程序进行分析
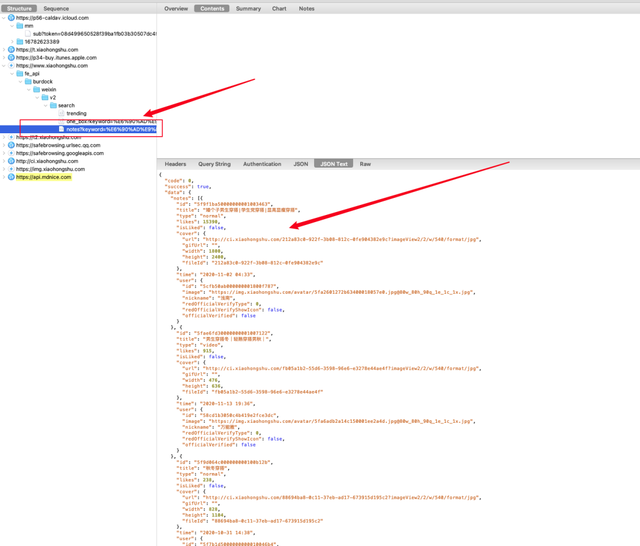

按照我的路径,你可以发现列表中的数据已经被我们抓住了。
但你觉得结束了吗?
不不不
通过这个包捕获,我们知道数据可以通过这个api接口获得。
但是当我们把所有的爬虫写好的时候,我们会发现头中有两个很难的参数。
授权”和“x符号”
这两样东西是不断变化的,不知道从哪弄来的。
因此
2、使用mitmproxy来进行抓包
事实上,通过查尔斯抢包,我们已经清楚了整体的抢包思路。
也就是说,获取' authorization '和' x-sign '两个参数,然后对url发出get请求。
这里使用的mitmproxy和查尔斯几乎一样,是一个抓包工具。
但是mitmproxy可以用Python执行。
这样舒服多了。
举个简单的例子。
defrequest(流):
Print(flow.request.headers)在mitmproxy中为我们提供了这样一个方法,这样我们就可以通过request对象截取请求头中的url、cookies、主机、方法、端口、方案等属性。
这不正是我们想要的吗?
我们直接截取参数‘授权’和‘x符号’。
然后填写标题。
整个完成了。
以上就是我们整个爬行的想法。让我们解释一下如何编写代码。
事实上,代码并不难写。
首先,我们必须拦截搜索api的流,这样我们就可以从中获取信息。
如果‘https://www.xiaohongshu.com/fe _ api/牛蒡/微信/v2/search/notes’流入. request.url3360我们判断流的请求中是否存在搜索API的url。
来决定我们需要抓取的请求。
authorization=re . find all(' authorization ',)。*?'(.*?)' \)',字符串(flow.request.headers))[0]
x_sign=re.findall('x-sign ',)。*?'(.*?)' \)',字符串(flow.request.headers))[0]
Url=flow.request.url通过上面的代码,我们可以得到三个最关键的参数,然后我们将共同解析json。
最后,我们可以得到我们想要的数据。
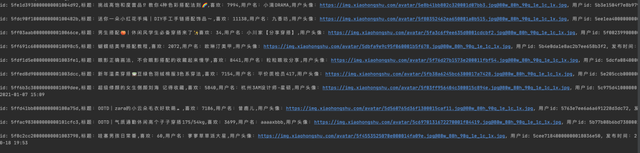
如果你想得到一个单独的数据,你可以得到文章id并获取它。
' https://www . xiaohongshu.com/discovery/item/'
此页眉需要有cookies。当你随意访问一个网站时,你可以得到饼干。目前看来是固定的。
最后,您可以将数据放入csv。
总结
其实小红书爬虫的爬行并不是特别难,关键在于思维和使用的方法。
看完以上,你掌握了用Python爬小红书的方法了吗?如果您想学习更多技能或了解更多相关内容,请关注行业资讯频道。感谢阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/49011.html