
很多新手对于如何使用Python抓取酷炫音乐不是很清楚。为了帮助大家解决这个问题,下面小编就为大家详细讲解一下。需要的人可以学习,希望你能有所收获。
前两天听了酷我音乐官网的音乐,感觉上面的音乐还不错。我想爬上去。一开始一点线索都没有,但最后有了实现的想法,那就是通过两个json文件得到你想听的音乐。


在此插入图片描述
需要的Python模块
。实现这个过程的主要模块有requests、json、urllib.request和urllib.parse requests模块用于请求相应的数据(在这种情况下,获取json数据),json模块用于处理json数据(将json数据转换为字典,主要使用json.loads()方法)、urllib.request(使用其urlretrieve()方法下载音乐)、urllib . parse(使用其quote()方法对输入字符串进行编码)。
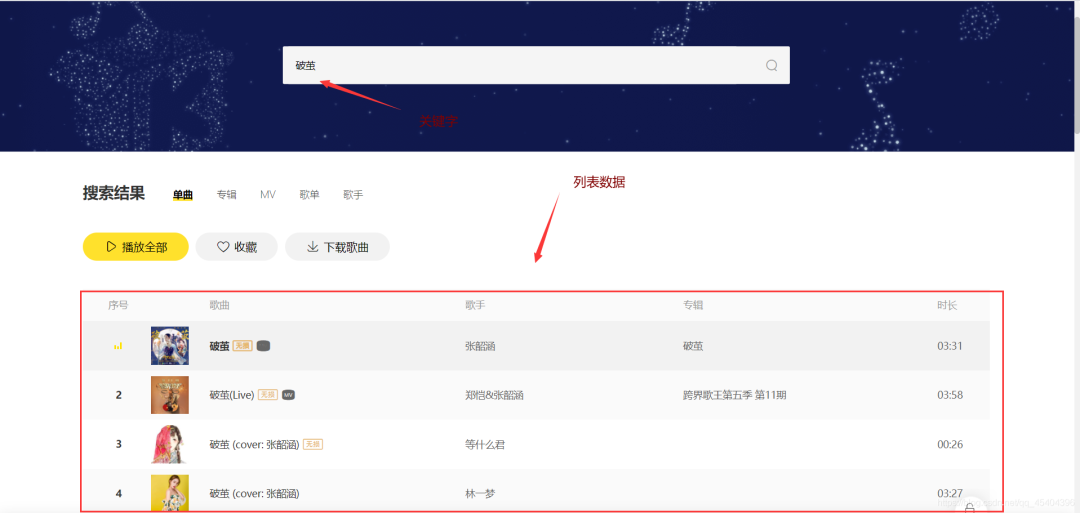
00-1010首先我们需要来到酷乐官网(http://www.kuwo.cn/),在输入框输入关键词。边肖的输入是:破茧进入,可以得到对应的歌单。但是,这些数据都是动态加载的。如果您使用请求模块直接请求该网站,则不可能获得这些数据。这时,我们可以按下电脑键盘F12,进入开发者模式,点击网络下的XHR,找到其中一个歌单。
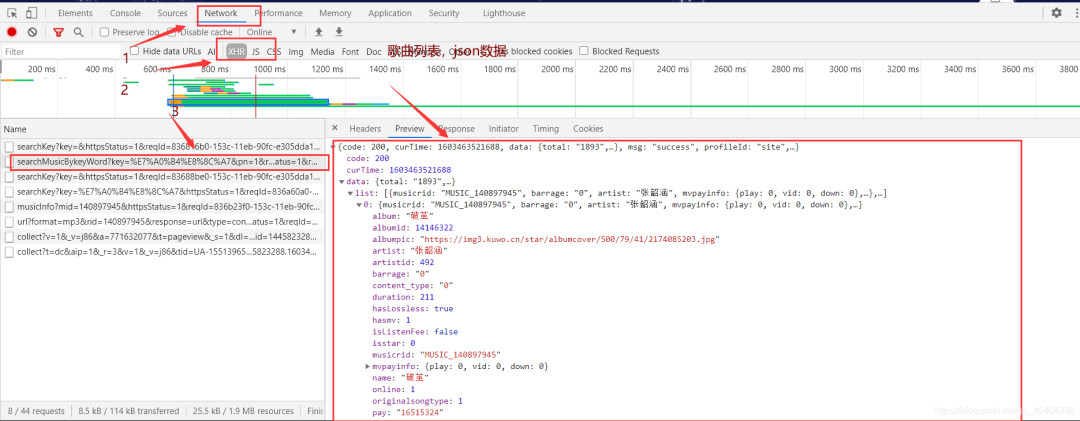
我们需要在这些歌曲中获得相应的数据,如下所示:
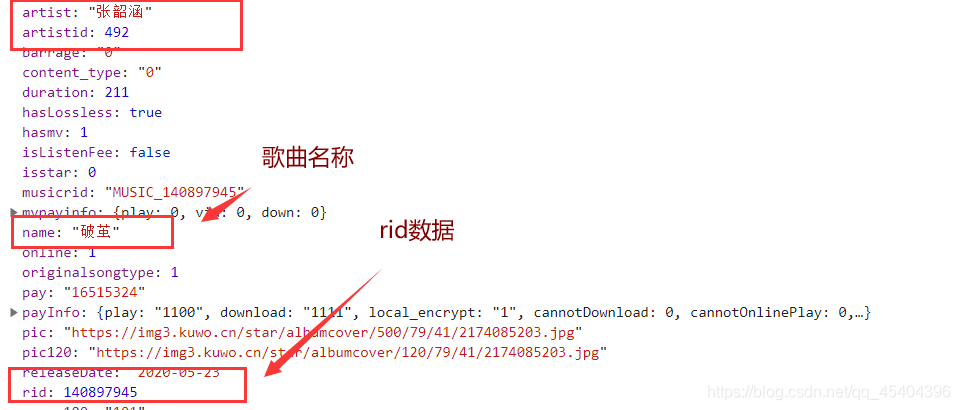
对应于名称和艺术家关键字的值是显示和最终的. mp3文件名,对应于rid关键字的值用于以下过程。
当然,访问这个网站不是很简单,所以你需要添加一个请求头。参考代码如下:
音乐名称=输入('请输入歌曲名称:')
encodName=引号(musicName)
URL=' https://www . kuwo.cn/API/www/search/search musicbykeyword?key={}pn=1rn=30httpsStatus=1 '。格式(encodName)
refer=' https://www . kuwo.cn/search/list?key={} '。格式(encodName)
#请求标题
标题={ 0
cookie ' : ' _ ga=GA1 . 2 . 202100764004hm _ lvt _ CDB 524 f 42 f 0 ce 19 b 169 a 8071123 a 4797=1602479334,1602673632;_ GID=GA1 . 2 . 168402150 . 16026736333hm _ lpvt _ CDB 524 f 42 f 0 ce 19 b 169 a 8071123 a 4797=1602673824;kw _ token=5LER5W4ZD1C ',
csrf ' : ' 5LER5W4ZD1C ',
referer ' :“{ 0 }”。格式(引用者),
用户代理' : ' Mozilla/5.0(windowsnt 10.0;Win64x64)applebwebkit/537.36(KHTML,likeGecko)Chrome/86.0.4240.75
nbsp;Safari/537.36",
}
response=requests.get(url=url,headers=headers)
dict2=json.loads(response.text)
misicInfo=dict2['data']['list'] # 歌曲信息的列表
musicNames=list() # 歌曲名称的列表
rids=list() # 存储歌曲rid的列表
for i in range(len(misicInfo)):
name=misicInfo[i]['name']+'-'+misicInfo[i]['artist']
musicNames.append(name)
rids.append(misicInfo[i]['rid'])
print('【{}】-{}->>>{}'.format(i+1,int(random.random()*10)*'#$',name))
我们选择上面列表中歌曲进行试听,可以发现,在刚才那个下面有一个这样的网址,里面也是一个json数据,放有我试听歌曲的下载链接。如下: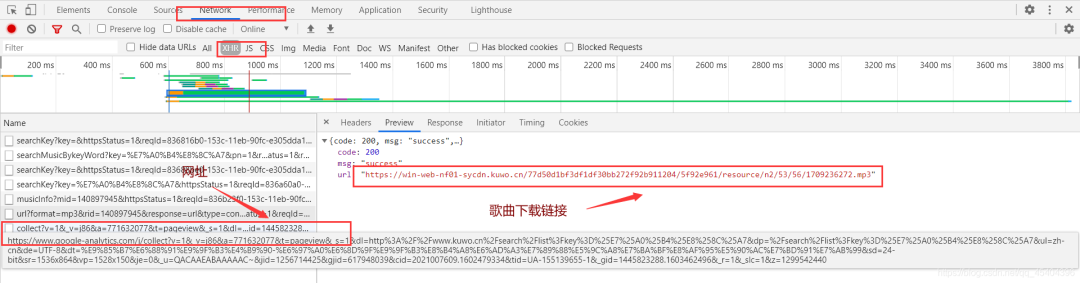
对这个网址进行分析可以得知,需要刚才我们的那个 rid 数据才能访问到相应的json数据。网址为:http://www.kuwo.cn/url?format=mp3&rid=**140897945**&response=url&type=convert\_url3&br=128kmp3&from=web&t=1603463521198&httpsStatus=1,也许读者得到的那个网址长度比我这个长一些,我这个是去掉最后面的那个参数的,因为我发现没有最后的那个参数,依旧可以访问到相应的数据。
最终代码和运行结果
参考代码如下:
from urllib.request import urlretrieve
from urllib.parse import quote
import requests
import random
import json
musicName=input('请输入歌曲名称:')
encodName=quote(musicName)
url='https://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={}&pn=1&rn=30&httpsStatus=1'.format(encodName)
referer='https://www.kuwo.cn/search/list?key={}'.format(encodName)
# 请求头
headers = {
"Cookie": "_ga=GA1.2.2021007609.1602479334; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1602479334,1602673632; _gid=GA1.2.168402150.1602673633; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1602673824; kw_token=5LER5W4ZD1C",
"csrf": "5LER5W4ZD1C",
"Referer": "{}".format(referer),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
}
response=requests.get(url=url,headers=headers)
dict2=json.loads(response.text)
misicInfo=dict2['data']['list'] # 歌曲信息的列表
musicNames=list() # 歌曲名称的列表
rids=list() # 存储歌曲rid的列表
for i in range(len(misicInfo)):
name=misicInfo[i]['name']+'-'+misicInfo[i]['artist']
musicNames.append(name)
rids.append(misicInfo[i]['rid'])
print('【{}】-{}->>>{}'.format(i+1,int(random.random()*10)*'#$',name))
id=int(input('请输入歌曲序号:'))
musicRid=rids[id-1]
url2='https://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3&br=128kmp3&from=web&t=1602674521838&httpsStatus=1'.format(musicRid)
headers2={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
response2=requests.get(url=url2,headers=headers2)
dict3=json.loads(response2.text)
downloadUrl=dict3['url']
path=input('请输入存储路径:')
urlretrieve(url=downloadUrl,filename=path+'\{}.mp3'.format(musicNames[id-1])) # 下载歌曲
运行结果:
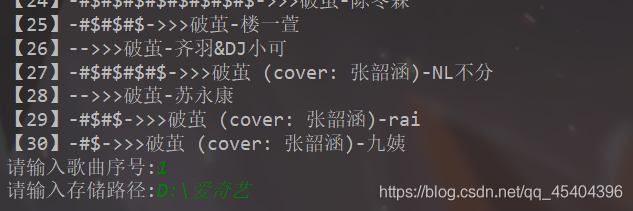
找到相应的目录,可以发现在这个文件夹下面多了一个.mp3文件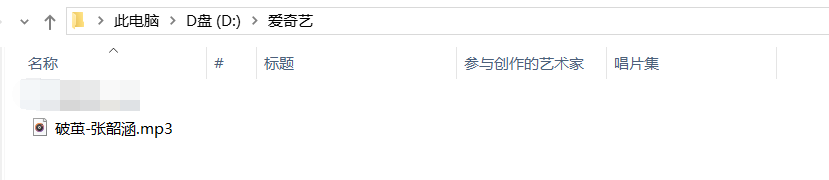
总结
首先,小编先声明一下:本程序参考代码仅供学习,切莫用于商业活动,一经被相关人员发现,本小编概不负责!
另外,需要指明的是希望读者一天不要多次运行本程序代码,从而减少服务其负担。
程序代码或许还有一定的不足!没有详细地分析这两个网址中的参数,读者有兴趣的话,可以尝试尝试。如果读者觉得小编的这篇文章还不错!离开的时候别忘了点上一个小小的赞!
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注行业资讯频道,感谢您对的支持。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/49013.html