
这篇文章是关于Python如何抓取当当APP数据的,边肖觉得挺实用的,所以想分享给大家学习。希望大家看完这篇文章能有所收获。话不多说,让我们和边肖一起看看。
场景
目标
:有时由于传统的抓取一些网页或应用的方法,由于对方的反抓取方案,很难抓取到想要的数据。此时,我们可以考虑使用“Appium”结合“mitmproxy”来抓取数据。
其中,Appium负责驱动App自动运行,mitmproxy负责截取请求的数据保存到数据库。
今天的目标是抓取当当的所有数据,保存在MongoDB数据库中。
准备工作
首先,应该在PC上安装Charles和Appium Desktop,并配置mitmproxy环境。
#安装mitmproxy依赖包。
pip3installmitmproxy
#安装pymongodb。
Pip3installpymongo此外,还需要准备一部安卓手机,在PC上配置安卓开发环境。
爬取思路
1.配置手动代理后,打开Charles实时捕获客户端发起的网络请求。
打开当当网的产品搜索页面,搜索关键字“Python”,在Charles中可以看到当前请求的URL地址包括:“word=Python”。
编写mitmproxy的脚本文件,重写response()函数,过滤请求的URL,整理出有用的数据保存在MongoDB数据库中。
classDangDangMongo(对象):
'''
初始化MongoDB数据库。
'''
def__init__(self):
self . client=Mongoclient(' localhost ')
self.db=self.client['admin']
self.db.authenticate('root ',' xag ')
self .当当_book_collection=self.db['当当_book']
defresponse(流):
#过滤请求的网址。
if ' keyword=Python ' in request . URL :
data=JSON . loads(response . text . encode(' utf-8 ')
#书
products=data . get(' products ')or one
product_datas=[]
for production in product cts 3360
#图书编号
product_id=product.get('id ')
(=NationalBureauofStandards)国家标准局
p; # 书名
product_name = product.get('name')
# 书价格
product_price = product.get('price')
# 作者
authorname = product.get('authorname')
# 出版社
publisher = product.get('publisher')
product_datas.append({
'product_id': product_id,
'product_name': product_name,
'product_price': product_price,
'authorname': authorname,
'publisher': publisher
})
DangDangMongo().dangdang_book_collection.insert_many(product_datas)
print('成功插入数据成功')
先打开客户端的手动代理监听 8080 端口,然后执行「mitmdump」命令,然后滚动商品界面,发现数据到写入到数据库中了。
mitmdump -s script_dangdang.py
2. 下面我们要利用 Appium 帮我们实现 自动化。
首先打开 Appium Desktop,并启动服务。
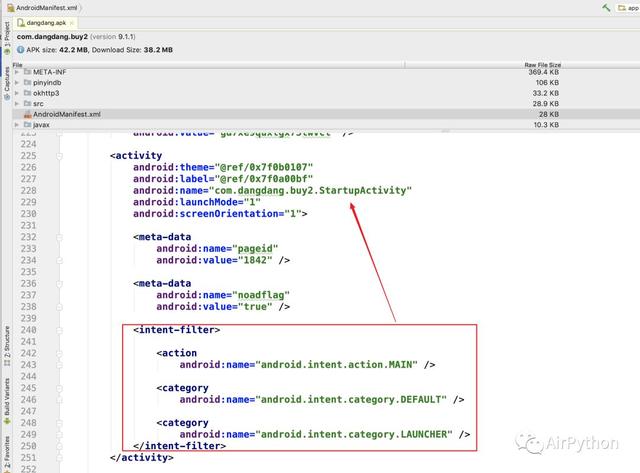

获取到包名和初始 Activity 后,就可以利用 WebDriver 去模拟打开当当网 APP。
self.caps = {
'automationName': DRIVER,
'platformName': PLATFORM,
'deviceName': DEVICE_NAME,
'appPackage': APP_PACKAGE,
'appActivity': APP_ACTIVITY,
'platformVersion': ANDROID_VERSION,
'autoGrantPermissions': AUTO_GRANT_PERMISSIONS,
'unicodeKeyboard': True,
'resetKeyboard': True
}
self.driver = webdriver.Remote(DRIVER_SERVER, self.caps)
接着使用 Android SDK 自带的工具 uiautomatorviewer 获取到元素信息,使用 Appium 中的 WebDriver 去操作 UI 元素。
第一次打开应用的时候,可能会出现红包雨对话框、新人专享红包对话框、切换城市对话框,这里需要通过元素 ID 获取到关闭按钮,执行点击操作来关闭这些对话框。
这里创建一个 新的线程 来单独处理这些对话框。
class ExtraJob(threading.Thread): def run(self): while self.__running.isSet(): # 为True时立即返回, 为False时阻塞直到内部的标识位为True后返回 self.__flag.wait() # 1.0 【红包雨】对话框 red_packet_element = is_element_exist(self.driver, 'com.dangdang.buy2:id/close') if red_packet_element: red_packet_element.click() # 1.1 【新人专享券】对话框 new_welcome_page_sure_element = is_element_exist(self.driver, 'com.dangdang.buy2:id/dialog_cancel_tv') if new_welcome_page_sure_element: new_welcome_page_sure_element.click() # 1.2 【切换位置】对话框 change_city_cancle_element = is_element_exist(self.driver, 'com.dangdang.buy2:id/left_bt') if change_city_cancle_element: change_city_cancle_element.click() extra_job = ExtraJob(dangdang.driver) extra_job.start()
接下来就是点击搜索按钮,然后输入内容,执行点击搜索对话框。
# 1.搜索框 search_element_pro = self.wait.until( EC.presence_of_element_located((By.ID, 'com.dangdang.buy2:id/index_search'))) search_element_pro.click() search_input_element = self.wait.until( EC.presence_of_element_located((By.ID, 'com.dangdang.buy2:id/search_text_layout'))) search_input_element.set_text(KEY_WORD) # 2.搜索对话框,开始检索 search_btn_element = self.wait.until( EC.element_to_be_clickable((By.ID, 'com.dangdang.buy2:id/search_btn_search'))) search_btn_element.click() # 3.休眠3秒,保证第一页的内容加载完全 time.sleep(3)
待第一页的数据加载完全之后,可以一直向上滚动页面,直到数据全部被加载完全,数据会由 mitmproxy 自动保存到 MongoDB 数据库当中。
while True:
str1 = self.driver.page_source
self.driver.swipe(FLICK_START_X, FLICK_START_Y + FLICK_DISTANCE, FLICK_START_X, FLICK_START_X)
time.sleep(1)
str2 = self.driver.page_source
if str1 == str2:
print('停止滑动')
# 停止线程
extra_job.stop()
break
print('继续滑动'
结果
首先使用 mitmdump 开启请求监听的服务,然后执行爬取脚本。
App 会自动打开,执行一系列操作后,到达商品界面,然后自动滑动界面,通过 mitmproxy 自动把有用的数据保存到 MongoDB 数据库中。
以上就是Python怎么爬取当当网APP数据,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注行业资讯频道。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/49015.html
