
计算机编程语言如何爬取腾讯招聘信息,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
1. 目标
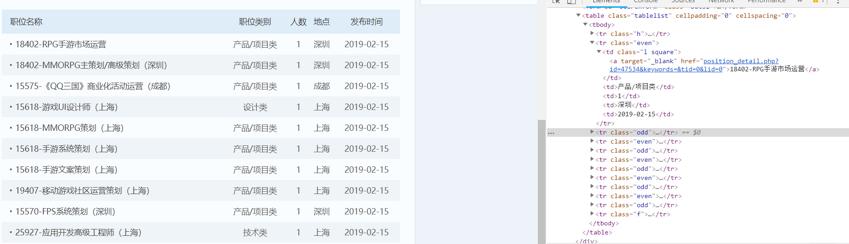
目标:https://hr.tencent.com/position.php?start=0#a
爬取所有的职位信息信息
职位名
职位全球资源定位器(统一资源定位符)
职位类型
职位人数
工作地点
发布时间

3. 编写爬虫程序
3.1. 配置需要爬取的目标变量
classTecentjobItem(剪贴簿。项目):
# define fields foryourttemherelike :
职位名称=剪贴簿.字段()
positionlink=scrapy .字段()
位置类型=剪贴簿。字段()
peopleNum=剪贴簿.字段()
工作地点=报废。字段()
出版时间=剪贴簿。菲尔德(3.2. 写爬虫文件scrapy)
#-*-coding:utf-8-*-
进口废料
从埃森特乔布。items importtecentjobitem
classTencentSpider(剪贴簿。蜘蛛):
名称='腾讯'
允许的_域=['腾讯。com ']
网址=' https://HR .腾讯。com/positionPHP?开始='
偏移=0
start _ URL=[URL字符串(偏移量)]
defparse(自我,响应):
foreachinresponse。XPath('//tr[@ class='偶数]|//tr[@class='奇数']'):
#初始化模型对象
item=TecentjobItem()
项目['职位名称']=每个。XPath(' .td[1]/a/text()').extract()[0]
项目['位置链接']=每个。XPath(' .TD/1/a/extract()[0]
项目[' position TYPe ']=每个。xpath(' .td[2]/text()').extract()[0]
项目[' PeopleNum ']=每个。xpath(' .td[3]/text()').extract()[0]
项目['工作位置']=每个。xpath(' .td[4]/text()').extract()[0]
项目[' PublishTime ']=每个。xpath(' .td[5]/text()').extract()[0]
yielditem
ifself.offset100:
自偏移=10
#将请求重写发送给调度器入队列、出队列、交给下载器下载
#拼接新的卢尔,并回调从语法上分析函数处理反应
#屈服了。请求(网址,回调=self.parse)
屈服了。3.3. 编写yield需要的管道文件
importjson
classTecentjobPipeline(对象):
def__init__(self):
自我。filename=open('腾讯。JSON ',' wb ')
defprocess_item(自身、项目、蜘蛛):
text=json.dumps(dict(item),confirm _ ascii=False)' \ n '
自我。文件名。写(文字。编码(' utf-8 ')
返回项目
defclose_spider(自我,蜘蛛):
自我。文件名。close()3.4. setting中配置请求抱头信息
DEFAULT _ REQUEST _ HEADERS={ 0
用户代理: ' Mozilla/5.0(window snt 10.0;win 64x 64)applebwebkit/537.36(KHTML,likeGecko)Chrome/71。0 .3578 .98 safari/537.36 ',
接受' : '文本/html,应用程序/xhtml xml,应用程序/XML;q=0.9,*/*;q=0.8 ',
接受-语言:'en ',
}看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注行业资讯频道,感谢您对的支持。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/49728.html
