
本文向您展示了如何使用Python爬虫来抓取代理IP。内容简洁易懂,一定会让你眼前一亮。希望通过这篇文章的详细介绍,你能有所收获。
不知道大家在访问网站的时候有没有遇到过这样的状况就是被访问的网站会给出一个提示,提示的显示是“访问频率太高”,如果在想进行访问那么必须要等一会或者是对方会给出一个验证码使用验证码对被访问的网站进行解封。之所以会有这样的提示是因为我们所要爬取或者访问的网站设置了反爬虫机制,比如使用同一个IP频繁的请求网页的次数过多的时候,服务器由于反爬虫机制的指令从而选择拒绝服务,这种情况单单依靠解封是比较难处理的,所以一个解决的方法就是伪装本机的IP地址去访问或者爬取网页,也就是我们今天所有跟大家所说的代理IP
目前互联网上有很多代理IP,有免费的,也有付费的。免费但有效的代理很少,而且不稳定,所以付费可能更好。先说代理ip的试用,把可用的IP存到MongoDB,下次拿出来用。
运行平台:Windows。
Python版本:Python3.6。
IDE:崇高的文字
其他:Chrome浏览器。
简要过程如下:
步骤1:了解如何使用请求代理。
第二步:从代理网页抓取到ip和端口。
步骤3:检查已爬网ip是否可用。
步骤4:将已爬网的可用代理存储在MongoDB中。
第五步:从可用ip中存储的数据库中随机选择一个ip,测试成功后返回。
对于请求,代理设置相对简单,只需传入代理参数。
但是需要注意的是,在这里,我在这台机器上安装了包抓取工具Fiddler,并使用它在本地端口8888(使用Chrome插件SwitchyOmega)创建了一个HTTP代理服务,即代理服务为:127.0.0.1:8888。只要我们设置了这个代理,我们就可以成功地将本地ip切换到代理软件连接的服务器ip。

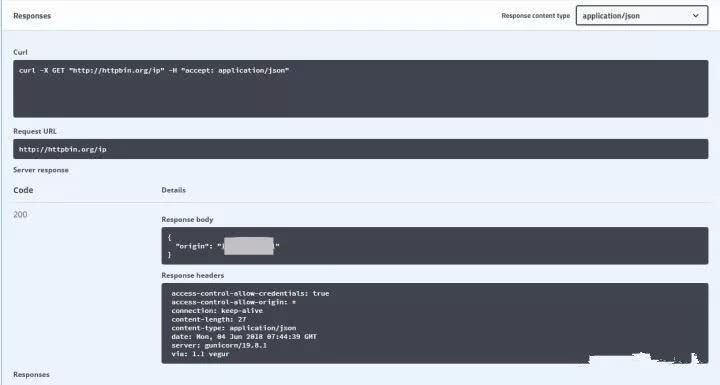
在这里,我使用http://httpbin.org/get作为测试网站。当我们访问这个网页时,我们可以得到所请求的信息,其中origin字段是客户端ip,我们可以根据返回的结果来判断代理是否成功。结果如下:
接下来,我们开始抓取代理ip。首先我们打开Chrome浏览器查看网页,找到了IP和端口元素的信息。
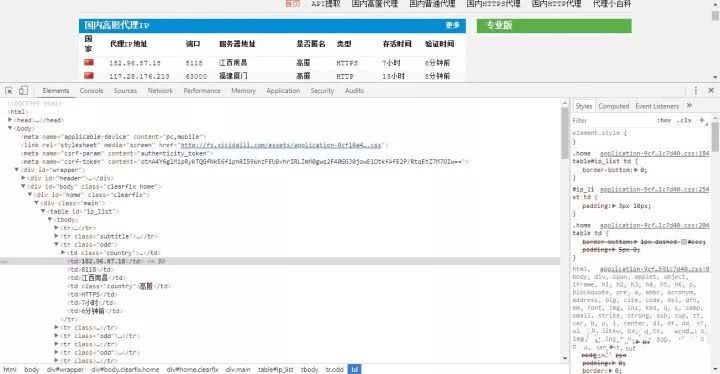
可以看出,代理ip将ip地址和相关信息存储在表中,因此我们在使用BeautifulSoup时可以轻松提取相关信息。但是,我们要注意被抓取的ip很可能是重复的,尤其是当我们抓取多个代理页面并同时将其存储在同一个数组中时,我们可以使用集合来移除重复的IP。

待抓取的Ip页面被抓取并存储在数组中,然后对其中的IPS进行逐一测试。
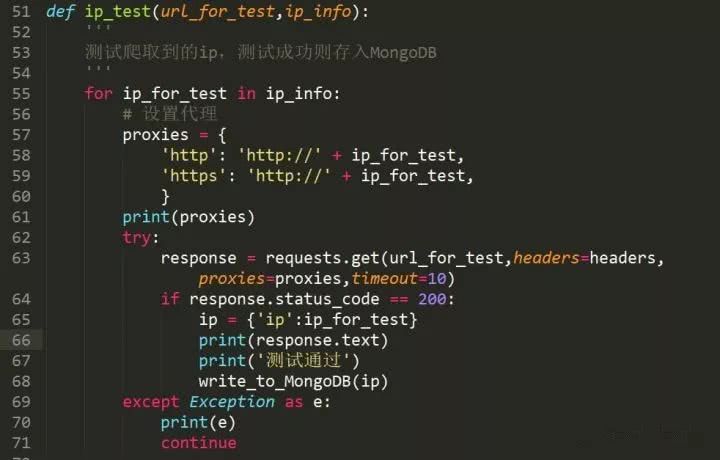
这里,我们使用上述请求设置代理的方法。我们使用http://httpbin.org/ip作为测试网站,它可以直接返回我们的ip地址,然后通过测试后存储在MomgoDB数据库中。
连接数据库,指定数据库和集合,并插入数据。
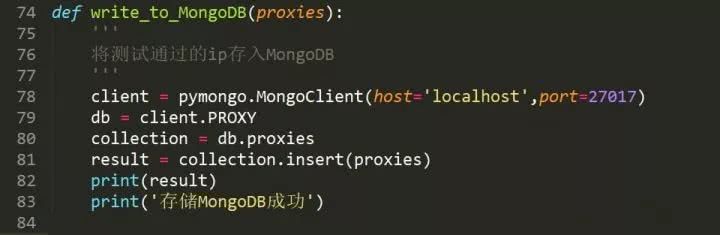
最后,运行并检查结果。
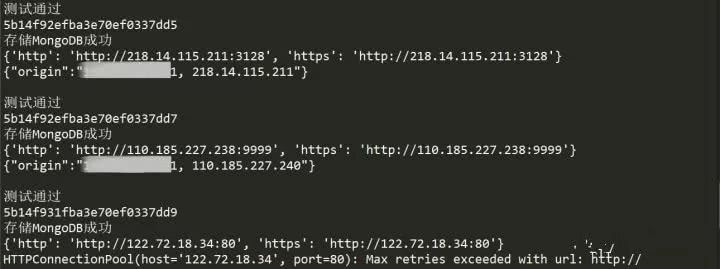
跑了一段时间后,很少看到连续通过三次测试。快速保存截图。其实毕竟是免费的代理IP,还是很有效的,生存时间真的很短。但是爬行量大,仍然可以找到并使用。如果只是用来练习,还是勉强够用。现在看看数据库中存储了什么。

因为爬取的页面不多,有效的IP也不多,我也不是很爬取,所以现在数据库里的IP也不多,但是都保存了。现在让我们看看如何随机取出它。
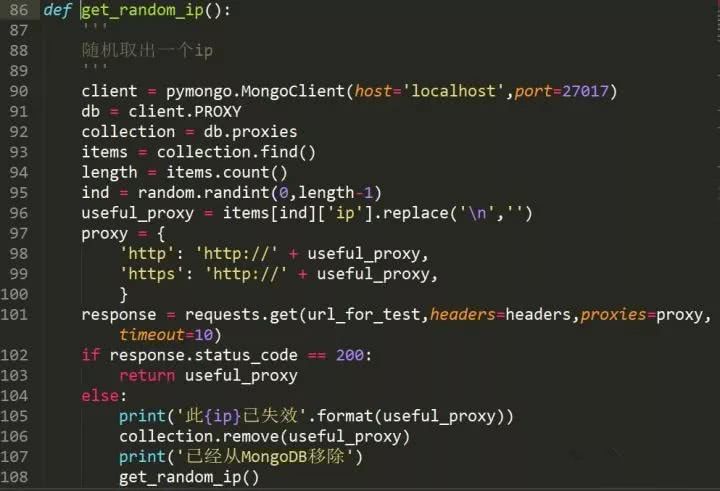
因为担心ip放入数据库一段时间后会失效,所以拿出来之前又测试了一遍。如果我成功返回ip,如果不成功,我会直接从数据库中删除它。
这样,当我们需要使用代理时,我们可以随时通过数据库取出它。
总代码如下:
zhihu.com/people/hdmi-blog
以上内容是如何用Python爬虫抓取代理IP。你学到什么知识或技能了吗?如果你想学习更多的技能或丰富你的知识储备,请关注行业信息渠道。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/54358.html