
相信很多没有经验的人,对于如何使用免费代理IP抓取数据都是一窍不通的。因此,本文总结了问题产生的原因及解决方法。希望你能通过这篇文章解决这个问题。
一.前言
玩爬虫的都无法避免各大网站反爬措施的限制。通过定时检查一个ip地址的流量来判断用户是否是“网络机器人”是很常见的,也叫爬虫。如果被识别,就会面临被ip封杀的风险,让你无法访问网站。

一般的解决方案是用代理ip爬行,但是收取的代理ip一般比较贵。互联网上有很多免费的代理ip网站,但由于时效性的影响,大部分地址无法使用。维护代理ip池有很多教程,就是把可以抓取检测的代理ip放入“代理池”,以后需要的时候再从中提取。在我看来,这个效率比较低,因为这样的IP地址很快就会失效。
二.抓取IP地址
让我们开始实战操作。
1.首先,我们来找一个免费的代理ip网站,如下图所示。
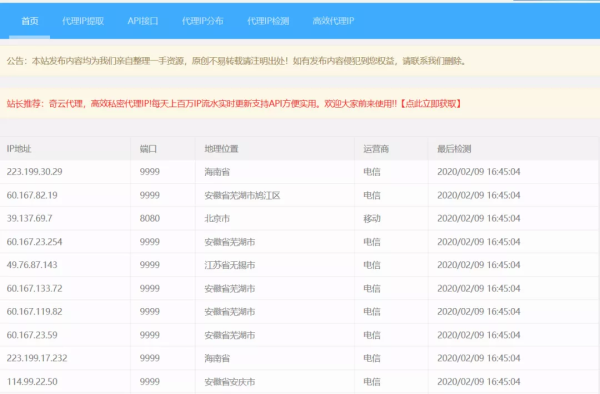

2.打开网页查看器,分析其网页元素的结构,如下图所示。
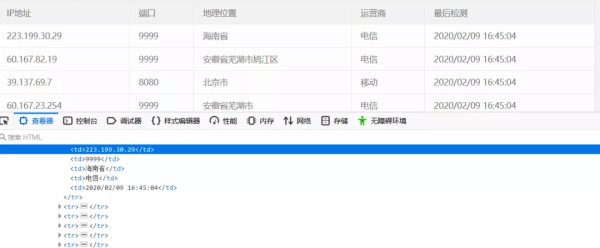
3.这是一个简单的静态网页。我们使用requests和bs4来下载ip地址和对应的端口,如下图所示。

4.每一行ip地址由5个标签组成,我们需要第一个标签(对应的ip地址)和第二个标签(对应的端口),所以从第一个开始,我们每5个取出IP地址(项[:33605]),从第二个开始,我们每5个取出对应的端口(项[1:5])。
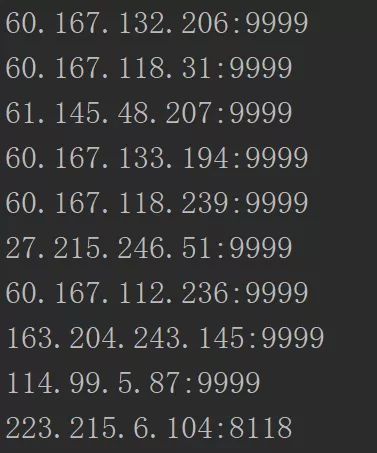
三.验证IP有效性
百度百科在这里被视为目标网站,但这个看似普通的网站的防爬措施极其严格,爬了几条内容后请求失败。在这里,我将以百度百科为例,演示如何使用免费代理ip。
1.首先,我爬下了12306上所有的火车站名称,但是没有归属信息。

2.然后通过站名构建百度百科url信息,分析网页元素,抓取火车站地址信息。网页元素如下图所示:
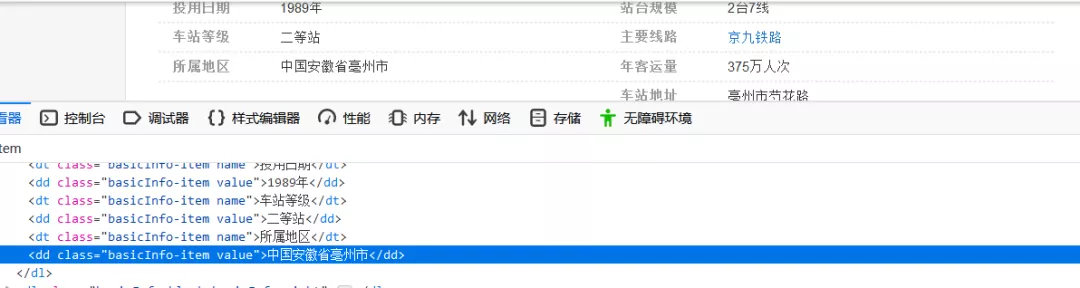
3.因此,我们只需要在class_='basicInfo-item '的标签内容中寻找“省”或“市”的字符,然后输出,最后添加一个while True循环,在ip可以正常抓取数据的时候打破这个循环;如果ip被禁止,立即重新请求一个新的ip进行爬网。直接代码如下图所示。
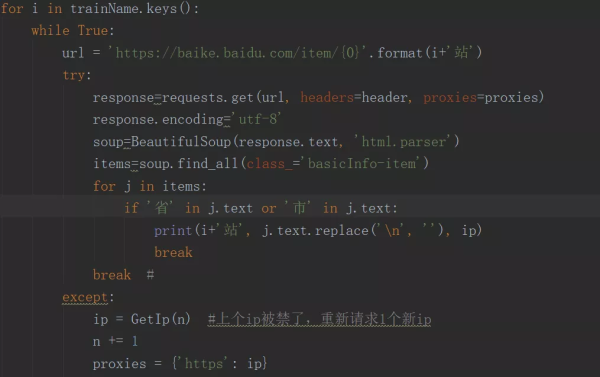
4.for循环是遍历所有火车站,尝试是检查ip是否仍然可以使用。如果没有,则在except中请求一个新的ip,爬行效果如下图所示:
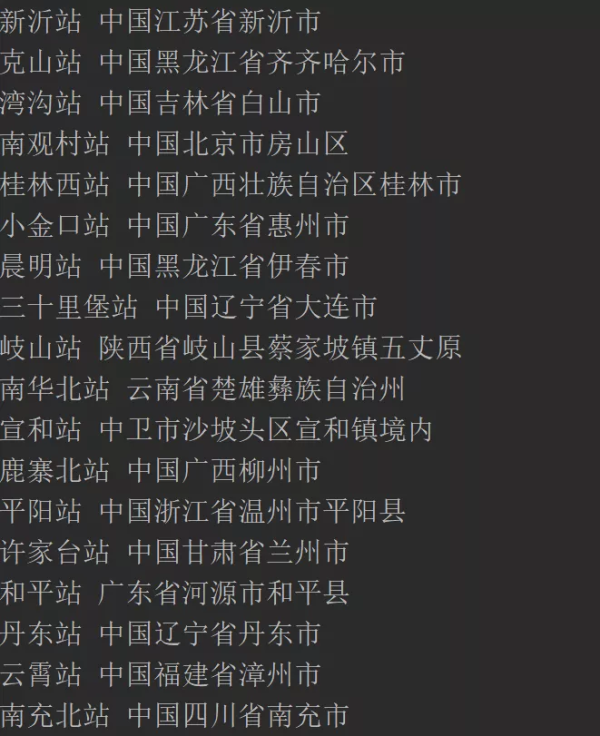
这种方法可以解决爬行动物下次被禁的问题。
主要介绍如何在IP代理网站上抓取可用的IP,以及如何通过Python脚本验证IP地址的时效性。如果爬虫被禁,可以用这个方法解决。
看完以上,你知道如何用免费的代理IP抓取数据吗?如果您想学习更多技能或了解更多相关内容,请关注行业资讯频道。感谢阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/54363.html