
本期,边肖将为您带来关于如何使用Python轻松将Pdf转换为Word的信息。文章内容丰富,从专业角度进行分析和叙述。看完这篇文章,希望你能有所收获。
每个人在日常的工作和学习中都会遇到一个问题,那就是把pdf中的文字内容转换成word,也就是从只读变成读写形式。面对这种情况,大多数人都使用在线工具,但在线工具是混合的,很难满足我们的需求。
今天,边肖带领大家使用python来实现如何将pdf内容转换为word文档。同时,我们还会将图片从pdf中提取出来,保存在我们指定的文件夹中。
01.文字的提取
我们需要做的第一件事是提取pdf格式的文本,如下图所示:
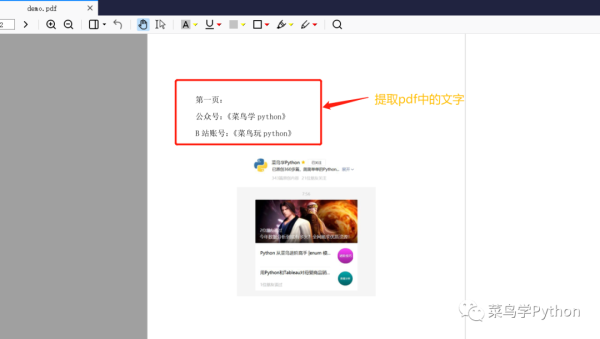
pdf中的汉字只允许只读,不能更改,所以我们要做的就是把Pdf中的文字信息提取出来,然后把提取出来的文字写入word文件中,这样以后就可以重写了。对于文本提取,我们使用pdfminer函数库,其主要功能如下图所示:
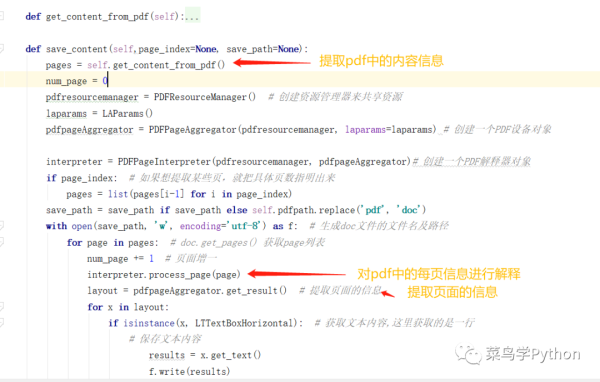
首先,程序使用get_content_from_pdf函数返回从pdf中提取的数据。
然后创建PDFResourceManager对象保存共享数据内容,创建PDFPageAggregator对象将资源对象处理成我们需要的格式,使用PDFPageInterpreter处理页面内容。
程序中的Page_index用来帮助我们设置需要提取哪些页面。对于我们需要提取的页面,页面信息由创建的PDFPageInterpreter对象解释。
最后,数据被PDFPageAggregator对象处理。
这里的布局包含从页面解析的所有类型的对象。包括文本、图片和其他信息。但是,边肖发现pdfminer对图像提取的效果很差,所以对于图像提取,边肖使用fitz库进行单独处理,取得了很好的图像提取效果。说到这里,我们先来看看文本处理的结果。
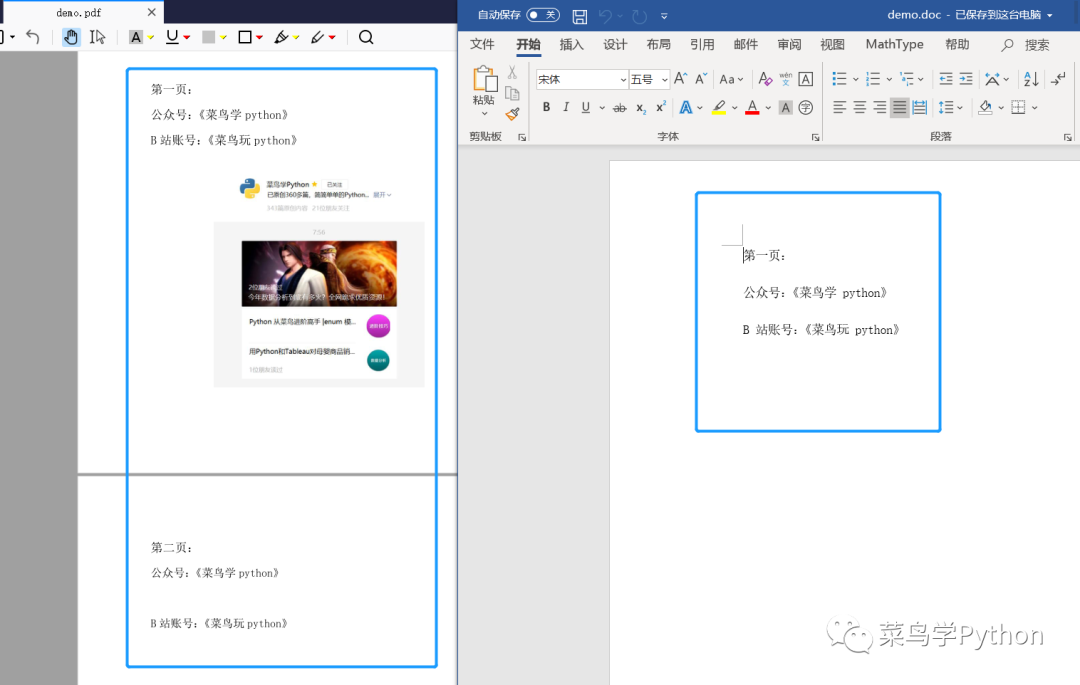

我们的pdf是一个两页的pdf文档,我们只让程序提取第一页的文本。从上图可以看出,程序完全提取了第一页的文本,没有任何错误。
02.图片的提取
随着文字的处理,我们来看看如何提取pdf格式的图片并保存到本地。对于图像提取,程序如下图所示:
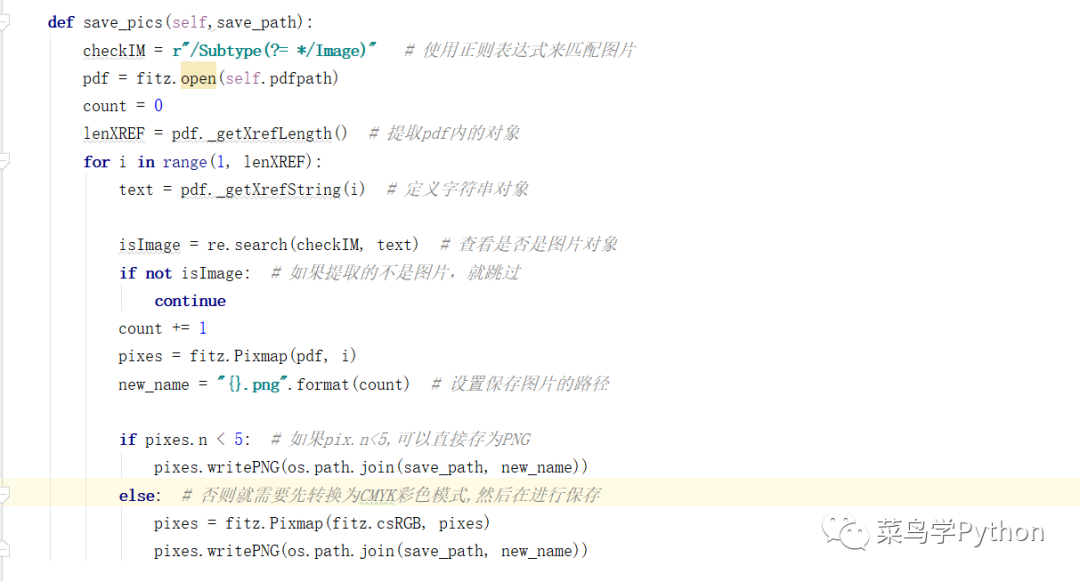
在上述程序中,我们使用fitz库提取pdf文档中的对象,然后通过字符串匹配来判断对象是否为图片类型。如果没有,我们可以直接跳过它们。
如果判断对象是图片类型,我们可以通过创建一个PixMap对象来提取图片,并保存到我们指定的路径。结果如下图所示:
从上图可以看出,我们提取的图片是正确的,从而达到了我们提取图片的目的,边肖也尝试过在没有任何压力的情况下提取很多图片。它可以在几秒钟内提取pdf文档的所有图片。
以上就是如何使用Python轻松将Pdf转换成Word,边肖为大家分享。如有类似疑惑,请参考以上分析了解。想了解更多,请关注行业信息渠道。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/54366.html