
如何开始使用Spark NLP?我相信很多没有经验的人都不知所措。因此,本文总结了问题产生的原因及解决方法。希望你能通过这篇文章解决这个问题。
2019年2月发布了
AI在企业中的应用
年度O 'Reilly企业AI应用报告。该报告调查了多个垂直行业的1300多名员工。调查内容包括受访企业生产环境中的AI项目,这些AI项目在企业中的应用情况,以及AI如何快速扩展为深度学习、人机互助系统、知识图谱和强化学习。
调查包括受访企业主要使用ML和AI的框架和工具。下图显示了用法摘要:
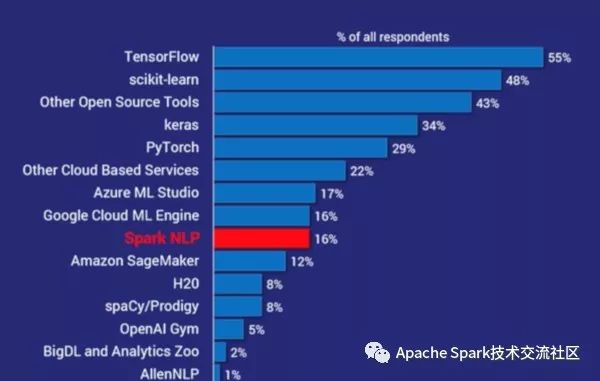
其中,Spark NLP在所有框架和工具中排名第7,是目前为止最受欢迎的NLP库,其受欢迎程度是spaCy的两倍。事实上,除了其他开源工具和其他云服务,Spark NLP是继scikit-learn、TensorFlow、Keras和PyTorch之后最受欢迎的AI工具。
高准确度,高性能以及扩展性
本次调查与近年来Spark NLP在医疗、金融、生命科学、招聘等领域的应用越来越多是一致的。根本原因是近几年NLP技术发生了重大变化。
00-1010在过去的3-5年间,自然语言领域深度学习的兴起使得算法的准确率越来越高,而spaCy、Stanford CoreNLP、ntlp、OpenNLP等传统算法在准确率上显然无法与这些最新的研究成果相比。
为了追求更高的精度和性能,业界不断生产最新的研究成果。下图是目前为止的总结(基于en_core_web_lg标准测试的F1值):
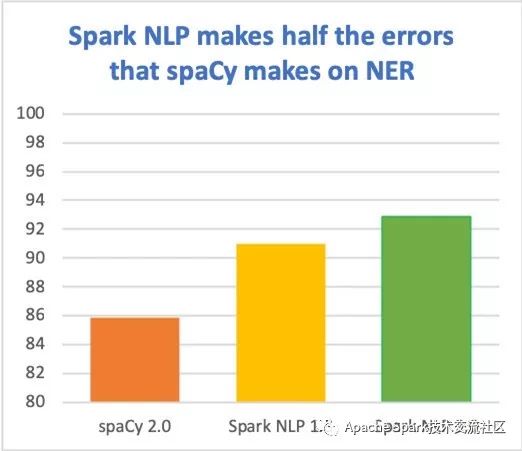

高准确度
由于Apache Spark的优化,无论是单机还是集群的性能都非常接近裸机,Spark NLP的性能可以比传统AI库快一个数量级,这受到它们设计的限制。
一年前,O'Reily发布了迄今为止最全面的产品级NLP库性能比较测试。下图左侧是spaCy和Spark NLP中简单流水训练的性能对比图。该测试基于单机配置(英特尔I5、4核、16GB内存):
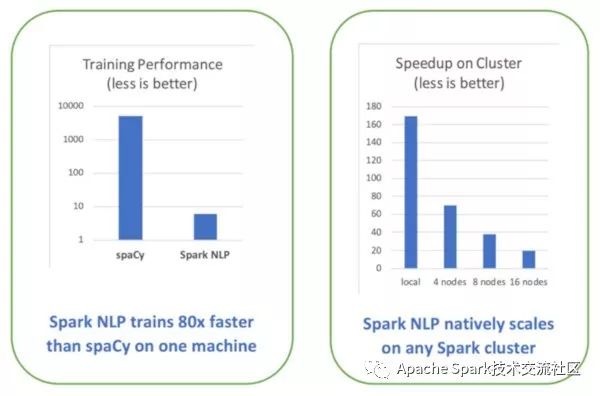
GPU是用于训练和推理编程的深度学习领域的主要趋势。使用TensorFlow进行深度学习使Spark NLP能够充分利用现代计算机平台——从nVida的DGX-1到英特尔的Cascade Lake处理器、传统库,无论是否使用深度学习技术,都需要重写代码才能充分利用这些新硬件的特性,而正是这些新硬件的特性将NLP性能提升了一个数量级。
00-1010在深度学习领域,模型训练、推理以及整个AI流水线能否从单机无缝迁移到集群变得越来越关键。spark NPL得益于Apache spark ML的原生构造,可以在Spark集群中任意扩展,Spark的分布式执行计划和Cache优化也可以帮助提升Spark NLP的性能。
00-1010
高性能
不同于面向研究的NLP库,如AllenNLP和NLP Architect。我们致力于为企业提供我们的Spark NLP库。
可扩展性
Spark NLP使用的是Apache 2.0许可协议,与SpaCy模型使用的Stanford CoreNLP(商业化需要付费)和ShareAlike CC许可协议不同。该协议完全免费商业化。
00-1010支持多语言编程,既提高了Spark NLP的受众,又避免了使用过程中的数据交换。比如SpaCy只支持Python,用户在使用过程中需要在JVM进程和Python进程之间交换数据,会导致架构复杂,性能下降。
00-1010除了社区贡献,Spark NLP还有一个专门的开发团队。Spark NLP基本上一个月发布两次。2018年,一共发布了26个版本。非常欢迎Spark NLP社区贡献代码、文档、模型和问题。
产品化的其他工作
产品级别的代码
Spark NLP 2.0其中一个主要的设计目标是用户可以在不了解Spark或TensorFlow的情况下使用Spark和TensorFlow平台。用户不需要知道Spark ML的估计器和转换器是什么,也不需要知道tensorFlow是什么。
graph或者session, 用户也可以使用Spark NLP 构建自己的模型,但是能够以最少时间和学习曲线完成,Spark NLP内置的15种训练流水和模型可以覆盖大部分的用户场景。
用户可以通过pip或者conda安装Spark NLP的python版本,Jupyter以及Databricks的安装以及配置细节可以参考 安装页面 (https://nlp.johnsnowlabs.com/docs/en/install), Spark NLP 被广泛应用在各种组件当中,包括Zepplin, SageMaker, Azure,GCP, Cloudera以及Vanilla spark,支持K8S和非K8S环境。
下图是展示的是情绪分析的简单例子:
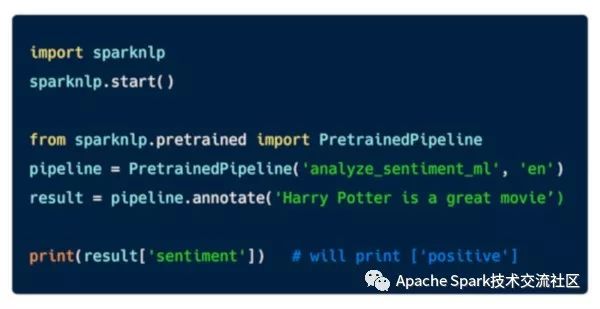
下图是利用Bert模型训练命名实体识别的例子:
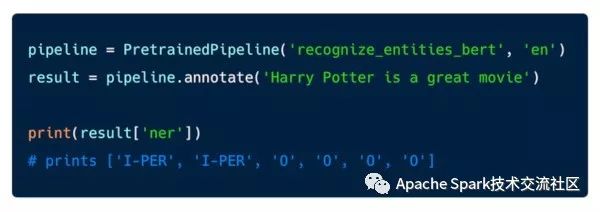
上述例子代码能够在spark集群上处理大量文本,其中有两个关键的方法 - annotate(), 该方法以string类型作为输入, transform(), 该方法的数据输入是spark 的data frame。
Scala
Spark NLP是用Scala语言编写的, 可以直接操作Spark Data Frame, 在这过程中数据零拷贝,可以充分利用Spark执行计划以及其他优化,因此对于Scala和Java开发者,使用Spark NLP非常方便。
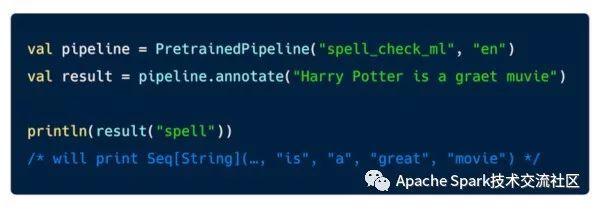
Spark NLP 可以Maven库中找到, 用户只要加上Spark NLP的依赖就可以使用它, 如果用户希望是有Spark NLP's OCR能力,需要安装额外的依赖。下图是个拼写检查的例子:
深入了解Spark NLP
Spark NLP为用户屏蔽许多复杂的细节,因此上面的代码片段都非常简单, 此外Spark NLP也提供了灵活性,用户可以根据自己的需求进行定制。Spark NLP针对训练领域的NLP模型做过深度优化。下面详细介绍Bert模型训练命名实体识别的Python代码:
-
sparknlp.start() 创建spark session。
-
PretrainedPipeline() 加载 explain_document_dl流水的英文版本, 预训练模型以及他们的依赖。
-
启动TensorFlow, TensorFlow的进程跟spark的处于同一个JVM进程,加载预先训练的Embeddings和深度学习的模型(例如NER), 模型可以自动在集群上分发以及共享。
-
annotate() 启动NLP的推理流程,并且分发各个阶段的算法流程。
-
NER阶段运行在tensorflow上,分别采用双向LSTM的神经网络以及CNN
-
Embeddings在推理过程用来将contextual tokens转换为vectors
-
最后结果以python字典的形式输出
GIVE IT A GO
Spark NLP主页包含大量的样例, 文档以及安装说明文档, 此外Spark NLP还提供了docker镜像, 用户可以很方便的在本地构建自己的环境。用户如果遇到任何问题, 用户可以登录Slack寻求帮助。
看完上述内容,你们掌握怎么进行Spark NLP使用入门的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注行业资讯频道,感谢各位的阅读!
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/79837.html