
本文向您介绍如何使用EMR Spark关系缓存跨集群同步数据。内容非常详细,有兴趣的朋友可以参考一下,希望对你有帮助。
利用关系缓存加速电磁辐射火花数据分析
背景
关系缓存是EMR Spark支持的重要功能。它主要通过预组织和预计算来加速数据分析,并提供类似于传统数据仓库物化视图的功能。除了提高数据处理速度,关系缓存还可以用于许多其他场景。本文主要介绍如何使用关系缓存来实现跨集群的数据表同步。
通过统一的数据湖管理所有数据是许多公司追求的目标。但在现实中,由于存在多个数据中心、不同的网络区域甚至不同的部门,不可避免地会出现很多不同的大数据集群,不同集群的数据同步需求是共通的。此外,集群迁移和站点迁移中涉及的新老数据同步也是一个常见问题。数据同步通常是一个痛苦的过程。迁移工具的开发、增量数据处理、读写同步、后续数据比对等都需要大量的定制开发和人工干预。基于关系缓存,用户可以简化这部分工作,以更低的成本实现跨集群的数据同步。
下面是一个具体的例子,展示如何通过EMR Spark关系缓存实现跨集群的数据同步。
00-1010假设我们有两个集群A和B,需要将activity_log表的数据从集群A同步到集群B,在整个过程中,会不断有新的数据插入到activity_log表中。集群A中activity_log的语句如下:
CREATETABLEactivity _ log(user _ idSTRING,act_typeSTRING,module_idINT,d_yearINT)使用JSONPARTITIONEDBY(d_year)
插入两条信息来表示历史信息:
INSERTINTOTABLEactivity _ logPARTITION(d _ year=2017)VALUES(' user _ 001 ',' NOTIFICATION ',10),(' user_101 ',' SCAN ',2)
为活动日志表建立关系缓存:
CACHETABLEactivity _ log _ syncrefreshsonmitdisablerewriteusing jsonpartitionedby(d _ year)LOCATION ' HDFS ://192 . 168 . 1 . 36:9000/user/hive/data/activity _ log ' as selectuser _ id,act_type,module_id,d _ yearFROMactivity _ log
REFRESH ON COMMIT意味着当源表数据更新时,缓存数据会自动更新。位置可以指定缓存数据的存储地址。我们将缓存的地址指向集群B的HDFS,从而实现集群A到集群B的数据同步,另外缓存的字段和分区信息与源表一致。
在集群B中,我们还使用以下语句创建了一个activity_log表:
CREATETABLEactivity _ log(user _ idSTRING,act_typeSTRING,module_idINT,d _ yearINT)using jsonpartitionedby(d _ year)LOCATION ' HDFS :///user/hive/data/activity _ log '
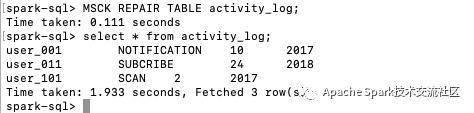
执行MSCK修复表活动日志,自动修复相关的元信息,然后执行查询语句。可以看到,在集群B中,已经可以找到在集群A的前一个表中插入的两条数据。


继续在群集A中插入新数据:
INSERTINTOTABLEactivity _ log partition(d _ year=2018)VALUES(' user _ 011 ',' SUBCRIBE ',24);
然后在集群B中执行MSCK修复表活动日志,并再次查询活动日志表。我们可以发现数据已经自动同步到集群b中的activity_log表中,对于分区表,当添加新的分区数据时,Relational Cache可以增量同步新的分区数据,而不是重新同步所有数据。
如果集群A中activity_log的新增数据不是通过Spark插入,而是通过Hive或其他外部方法导入Hive表中,用户可以通过REFRESH TABLE activity_log_sync语句手动或通过脚本触发同步数据,如果新增数据是按分区批量导入,还可以通过refresh table activity _ log _ sync与TABLE activity _ log partition(d _ year=2018)等语句增量同步分区数据。
关系缓存可以保证集群A和集群B中activity_log表的数据一致性,依赖activity_log表的下游任务或应用可以随时切换到集群B。同时,用户可以随时暂停向集群A中的activity_log表写入数据的应用或服务,指向集群B中的activity_log表,重启服务,从而完成上层应用或服务的迁移。完成后清理集群A中的活动_日志和活动_日志_同步。
通过关系缓存在不同大数据集群的数据表之间同步数据非常简单方便。此外,关系缓存还可以应用于很多其他场景,比如搭建二级响应OLAP平台、交互BI、Dashboard应用、加速ETL进程等。
下面介绍如何使用EMR Spark关系缓存跨集群同步数据。希望
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/79841.html
