
如何使用Mfuzz对时间序列表达模式进行聚类分析,很多新手都不是很清楚。为了帮助大家解决这个问题,下面小编就详细讲解一下。需要的人可以从中学习,希望你能有所收获。
在前一篇文章中,我们介绍了STEM软件,它可以对时间序列数据的基因表达模式进行聚类和分析。下面是另一个功能相同的R包Mfuzz。这个R包的地址如下
https://www . bio conductor . org/packages/release/bioc/html/Mfuzz . html
UZZ采用了一种新的聚类算法——模糊c均值算法,文献中称之为软聚类算法。与K-means等硬聚类算法相比,在一定程度上减少了噪声对聚类结果的干扰,该算法有效定义了基因与聚类之间的关系,即基因是否属于一个聚类,对应的值为memebership。
为了分析,我们只需要提供基因表达水平的数据。需要注意的是,Mfuzz默认你提供的数据是规范化的表达式级别,这意味着表达式级别必须在样本之间直接比较。对于FPKM和TPM,我们可以直接在样本之间进行比较。但是对于计数的量化结果,首先要对数据进行归一化,可以使用edgeR或者DESeq得到归一化后的数据进行后续分析。
假设已经有了归一化的表达式量,可以通过以下步骤得到聚类结果。
00-1010预处理包括读取数据,去除不同时间点表达过低或变化过少的基因。代码如下
x-read.table(
normalization . count . txt ',
row.names=1,
sep='\t ',
表头=T)
计数-数据.矩阵(x)
eset-new('ExpressionSet ',exprs=count)
#根据标准差去除样本间差异过小的基因。
Eset-filter.std(eset,min.std=0)需要注意的是,Mfuzz聚类需要一个ExpressionSet类型的对象,所以需要先构造这样一个带有expression quantity的对象。
00-1010聚类需要用一个数值来表征不同基因之间的距离。欧几里得距离用在Mfuzz中。因为普通欧氏距离的定义没有考虑不同维度之间的维度差异,需要先进行标准化。代码如下
ESET-standarded e(ESET)
1. 预处理
MFUZZ中的聚类算法需要提供两个参数。第一个参数是我们最终想要得到的簇数,这个参数是我们直接指定的。第二个参数叫做fuzzifier value,用小写字母M表示,一个最优值可以通过函数来计算。代码如下
#集群数量
c-6
#评估最佳M值
m-mestimate(eSet)
#聚类
Cl-mfuzz(eSet,c=c,m=m)将完整的聚类结果保存在对象Cl中。此对象的常见操作如下
#检查每个集群中的基因数量
cl $大小
#提取聚类下的基因
cl$cluster[cl$cluster==1]
#检查基因和聚类之间的隶属关系
Cl $会员
2. 标准化
代码如下
mfuzz.plot(
eSet,
cl,
mfrow=c(2,3),
New.window=FALSE)生成的图片如下
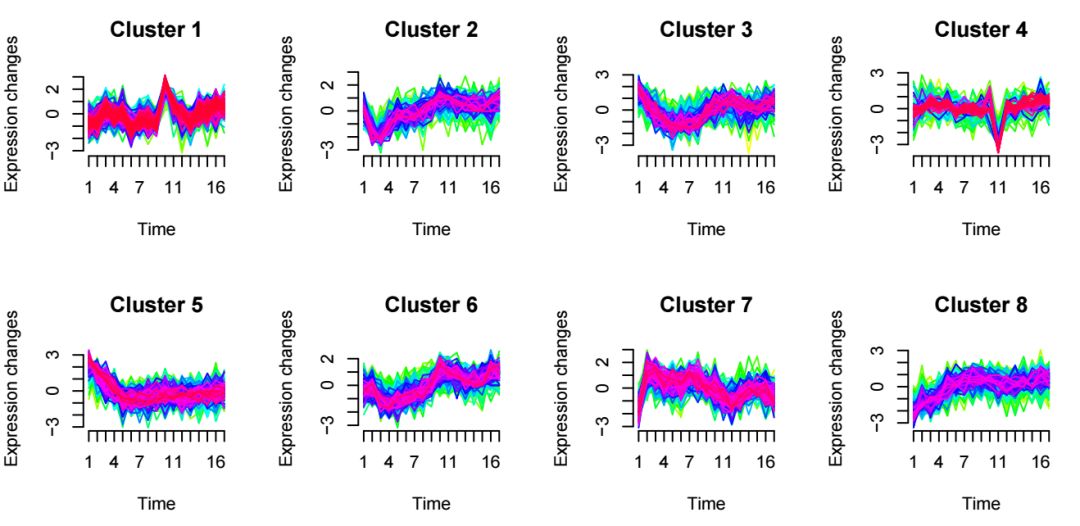

对于感兴趣的表达模式,可以通过上述用法提取该聚类下的基因列表,并通过GO/KEGG等功能富集分析进行进一步挖掘。
阅读以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注行业资讯频道,感谢您的支持。
内容来源网络,如有侵权,联系删除,本文地址:https://www.230890.com/zhan/80654.html